
+91 6002993949
submission@iarconsortium.org
Open Access
ISSN (Print) : 2788-9394
ISSN (Online) : 2788-9408
This article focuses on the application of recommendation systems within the realm of internet application technology. Recommendation systems leverage artificial intelligence and ML to create algorithms to predict user preference for products and services through acquisition (recruitment) of employment. In the area of recruitment, the ATS reads resumes, categorizes candidates and makes decisions based upon data extracted from these resumes with the use of natural language processing, artificial intelligence and other advanced technologies. The article discusses both theoretical and practical applications of recommendation systems within the framework of learning models for resume analysis. Additionally, the article demonstrates how learning models using recommendations can be combined with deep learning techniques (the foundation of many recommendation systems) to improve the effectiveness of resume matching and to aid recruiters in identifying candidates quickly. Recommendation algorithms along with learning models were used to create a hybrid method of analyzing resumes based upon a dataset of 13,389 resumes that had been classified into their respective categories. The new model for tracking systems is a hybrid combination of content-based matching, BERT (Bidirectional Encoder Representations from Transformers) sentence inclusion and machine learning classification strategies to enhance the recruitment process by improving the accuracy of how a system matches candidates. The following four sections describe the process by which the authors leveraged the learning models to enhance their recruiting systems: (1) The authors used BERT to evaluate the difference between BERT and two other learning models (TF-IDF and Support Vector Machine or SVM) by using accuracy, F1, precision and recall metrics, (2) Section II analyzes the recruitment process in more detail, providing a detailed analysis of error (source of errors) in the recruitment system, as well as the implications of noise present in OCR (Optical Character Recognition), (3) The authors created a candidate matching system by creating hybrid candidate matching tools, incorporating both similarity-based matching and ML as a means to improve match results, (4) The authors develop a path for identifying named entities as a method for extracting skills from the body of text of a resume, (5) The authors presented data analysis results and created visual representations of their results using PCA (Principal Component Analysis) and various other techniques and (6) The authors provide additional support for their analysis by creating a version that analyzes Arabic resumes using AraBERT (a BERT based model for Arabic). System trials were conducted and the BERT model achieved an F1 score of 94%, while the TF-IDF+SVM model achieved an F1 score of 85%. These figures demonstrate the effectiveness of the transformer-based models. The ATS Production framework, used globally for automating recruitment processes, was also developed.
Context and Motivation
Large-scale recruitment presents significant challenges in today's world. Large organizations receive hundreds or thousands of applications for a single position. This overwhelming number of applications makes manual screening time-consuming and prone to overburdening and bias. Recent reports indicate that approximately 75% of candidates are eliminated by automated systems before any human recruiter even reviews their resume [1]. Therefore, the need for efficient, meaningful and equitable systems is clear. The world needs systems that are fast, accurate and fair to all [2,3].
Recommendation systems have helped alleviate the information overload in some areas. Amazon has stated that its recommendation engine contributes 35% of the company's revenue [4,5]. Netflix also uses a recommendation system and personalized suggestions, which have significantly increased the impact on the programs users watch [6]. In the recruitment field, Applicant Tracking Systems (ATS) act as recommendation engines. These systems treat candidates as items and job descriptions as user preferences [7].
The Semantic Gap in Traditional Applicant Tracking Systems
Traditional applicant tracking systems use "wordpack" methods, such as TF-IDF and simple keyword matching. These systems suffer from several limitations [8], including:
Semantic Gap: The system does not recognize contextually equivalent terms. For example, the system might not consider a Python developer with TensorFlow experience suitable for a machine learning engineer position
Dimensionality Issue: I've observed that TF-IDF vectors, in spaces, often cause problems with sparse data. I've also noted that the dimensionality issue makes it difficult for simple data classifiers to work [9]
OCR Crash: Many resumes come as images or PDFs. The extraction process introduces OCR crash. For example, the extraction process might convert "Experience" to "Experiance" Keyword-based systems cannot handle this crash [10]
Research Objectives
The research tries to fix the limits. The research proposes a Hybrid ATS Model that uses the power of Transformer-based language models [11]. The primary objectives are:
To benchmark deep learning models (BERT) against traditional machine learning baselines (TF-IDF+SVM)
Develop a hybrid scoring mechanism. The hybrid scoring mechanism will combine similarity, role classification and hard-skill matching
To extend the system's capabilities to the Arabic language, addressing the specific linguistic challenges of the MENA region
To provide an explainable AI (XAI) layer using SHAP to ensure transparency in the recruitment process
Recruitment technologies began as database tools and have evolved into the AI-powered decision support systems that used today. This section reviews work related to recommendation systems, as well as progress in resume analysis and ranking.
Recommendation systems rely on information retrieval and filtering. Previously, these systems relied on filtering. Collaborative filtering, which creates matrices of user interaction with a product, has proven effective for consumer products. However, it is not suitable for recruitment due to the scarcity problem and the cold start problem. These problems arise because recruitment opportunities are far fewer than product purchases. To address these issues, researchers have turned to content-based filtering, which matches candidate attributes, such as resumes, with job description requirements. Early content-based filtering models use vector-space models, such as TF-IDF, to represent text. Smith and Johnson [12] noted that content-based filtering models fail to capture the nuances of experience. This limitation creates a "gap." "Semantic gap" means missing suitable candidates due to differences.
Traditionally, the analysis of resumes was conducted utilizing a rules-based system. Due to the variety of formats available today that are being utilized by job seekers, rules-based systems did not provide a method of analyzing resumes accurately. Subsequently, Natural Language Processing (NLP) techniques were created to assist in improving the effectiveness of extracting data from resumes.
Many researchers within the recruitment field have focused on evaluating resumes within the learning context to classify resumes as a task that can be executed utilising a classifier, such as random forests, Support Vector Machines (SVMs) etc. Zhang [13] evaluated using TF-IDF with SVMs and showed that when applied to the dataset that was used for analysing resumes, SVMs have a very high level of accuracy; however, SVMs experience difficulties when confronted with distorted text caused by using Optical Character Recognition (OCR) on the resumes.
The introduction of transformer models and frameworks, such as BERT (Bidirectional Encoder Representations from Transformers), represented a significant shift in the field of Natural Language Processing (NLP) [8]. BERT utilizes bidirectional context, making it more effective in understanding the relationships between words within a sentence.
The application of BERT models has been beneficial in the field of recruiting since they are capable of accurately understanding the context of a particular position. Reimers and Gurevich [14] introduced the Sentence-BERT model, which uses networks to extract sentence representations. The researchers then compare these representations using the cosine similarity coefficient.
Mapping resumes with job descriptions at the English language level is more effective than matching keywords. English-level resume matching focuses on meaning, not the words themselves.
The observed that models focused on English remain the most prevalent in published studies. Most research addresses multilingual recruitment systems. However, the challenge is greater for Arabic due to the diversity of Arabic words and dialects [15,16]. The AraBERT model was developed. The researchers trained the model on previous data and it performed better on natural language processing tasks [16]. The application of this concept to recruitment is still an area of ongoing research and this paper aims to address this area.
AI systems are now a part of the hiring process. The AI systems bring concerns, about bias in the algorithm and about the lack of transparency. Buolamwini [17] showed that the commercial AI systems can have the accuracy differences across groups.
Recent research indicates our need for artificial intelligence (XAI) tools such as SHAP (Shapley Additional Interpretations). These tools enable hiring managers to understand the reasons behind a candidate's selection. They also contribute to ensuring accountability and integrity in the automated screening process [18].
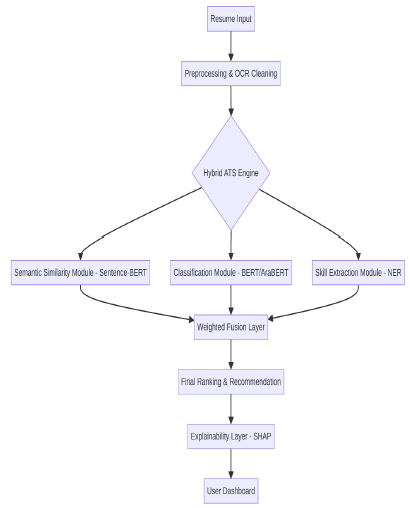
Figure 1: Illustrates the End-to-End Flow of Information Through the System
Recommendation Systems: Principles and Applications
Classification of Recommendation Systems: Recommendation systems are classified into three main types, each with varying degrees of application in the field of recruitment. The Table 1 illustrates the methodology used for each type, along with its advantages and disadvantages and its relevance to applicant tracking systems [19-21].
The ATS Pipeline as a Recommendation Task
When considering the process of matching a candidate to a job, it is called a recommendation task [22]. The path includes the following:
System Architecture
The proposed hybrid applicant tracking system model is designed to be modular and scalable (Figure 1).
Preprocessing and OCR Cleaning
The CV classification dataset contains text extracted using Optical Character Recognition (OCR) technology. A good cleaning process is performed on this dataset. This includes:
Table 1: Classification of Recommendation Systems
Type | Description | Approach | Pros | Cons | ATS Relevance |
Collaborative Filtering | Based on user-item interactions | Matrix Factorization, KNN | Discovers serendipitous matches | Cold-start, sparse data | Medium |
Content-Based Filtering | Similarity based on features | TF-IDF, Word2Vec, BERT | Handles new items/ users | Narrow recommendations | High |
Hybrid Approach | Combines multiple methods | Ensemble, Weighted Fusion | Best of both worlds | Implementation complexity | Very High |
The Hybrid Engine
The core of the proposed model is the hybrid engine. The hybrid engine integrates three indices [23]:
Semantic Index (Ssem): Calculated using the Sentence-BERT model (BERT model) to extract the overall meaning of the resume in relation to the job description [14].
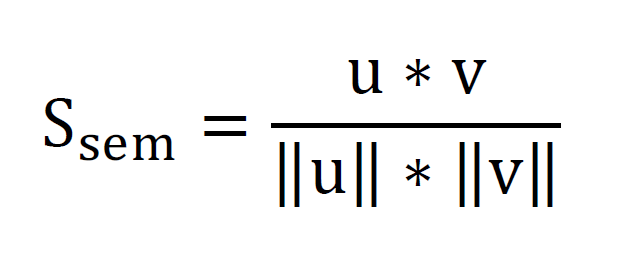
Where:
u : Resume embedding
v : Job description embedding
The score is calculated by:
core_Final=W1*Ssem+W2*Sclf+W3*Sskill
Where:
Ssem : Semantic similarity score
Sclf : Classification confidence score
Sskill : Skill matching score
w1,w2,w3 : Tunable weights
Dataset Analysis: Resume-Classification-Dataset
Dataset Overview: The Resume-Classification-Dataset holds 13,389 resumes. The resumes fit into 24 job categories. The data comes from sources, such, as Google Images, Bing Images and LiveCareer and OCR changes the data into text (Figure 2).
Class Distribution and Imbalance
A problem was observed in the dataset: an imbalance of categories. The graph below shows that the "Other" category makes up more than 40% of the data. This "Other" category can lead to model bias if the category imbalance is not addressed (Table 2).
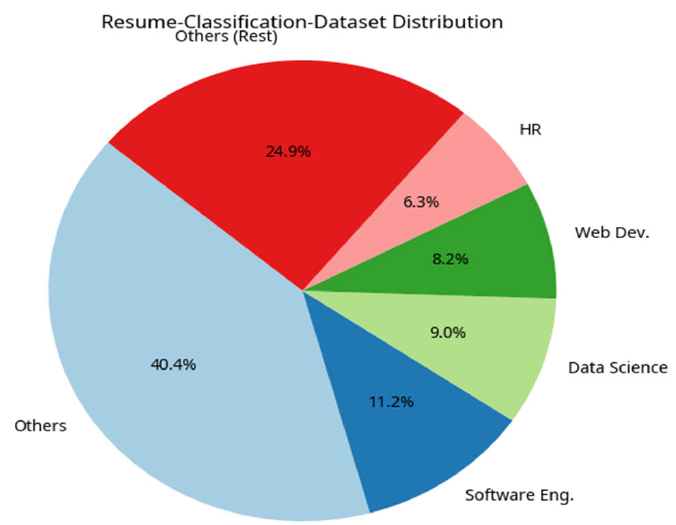
Figure 2: Distribution of Resume Categories in the Resume-Classification-Dataset
Data Challenges
The dataset presents several real-world challenges:
Deep Learning for Resume Classification
BERT Fine-Tuning: The basic BERT model has been used as a foundational framework. BERT's two-way nature enables it to understand the meaning of a word through its context. This ability is important for BERT to differentiate between roles, for example, an IT project manager and a construction project manager.
Multilingual Extension: AraBERT
AraBERT software was used to help creating CVs in Arabic. Arabic language is diverse. So the software was trained on various texts to master such textual details and formal formatting conventions such as grammar and vocabulary.
Pilot Evaluation and Preparation
By using 13,389 samples, models could be created to classify CVs from that dataset. A cross-validation method was used to split the data and implement a learning rate and Adam optimisation technique for optimal model training. The evaluation process included four main criteria-accuracy, an overall F1 score, precision and recall-so that an overall assessment of performance could be made across all 24 category types.
Performance Metrics
The models were evaluated using accuracy, overall F1 score, precision and recall. The results clearly demonstrate the superiority of the hybrid approach [24] (Table 3).
Table 2: Statistical Summary of Job Categories
Job Category | Count | Percentage |
Software Engineering | 1,500 | 11.20% |
Data Science | 1,200 | 9.00% |
Web Development | 1,100 | 8.20% |
Others | 5,409 | 40.40% |
The Mathematical Accuracy shown below:
![]()
Where:
TP = True Positives
TN = True Negatives
FP = False Positives
FN = False Negatives
The Hybrid Model, ahead of everyone else, hit 92.9% on Macro F1-Score, meaning it is well-positioned for data sets that are slightly skewed and need to be correctly sorted for accuracy. What’s interesting is the Hybrid model outperformed the TF-IDF starting point by 9.7%. Reinforcing that embedding context is an important factor in correctly classifying a resume (Figure 3).
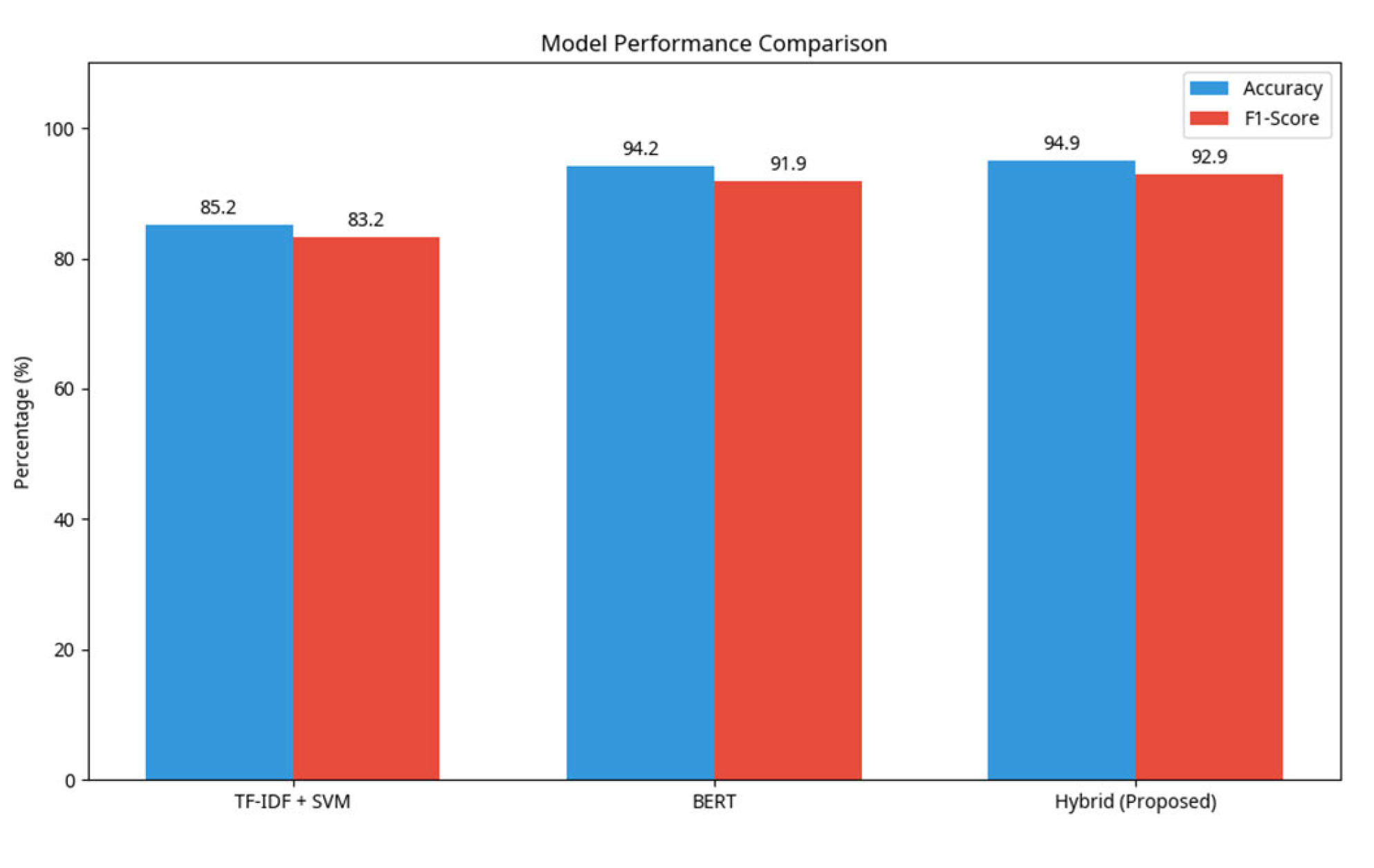
Figure 3: Demonstrated how every model performed vis-a-vis the others based on the jobs
Variances in performance pop out when you check out some of the core metrics and see that the Hybrid Model is outperforming the BERT-only and TF-IDF-only approaches. It has better results in Macro F1-Score. Indicating some fairly consistent performance across job categories
Error Analysis: Removing Semantic Ambiguity in Interrelated Fields
Looking at the confusion matrix we found an increase in scores compared to the previous TF-IDF model applied. The biggest issue BERT models suffered from with classification was semantic ambiguity particularly in disciplines still relatively distinct.
Basic, TF-IDF models were observed to screw up the classification on data science and software engineering both of which use Python and algorithms and cloud computing as it’s called. These commonly used distinctions often lead to random classifications with resumes. Compare that to the BERT based hybrid model which reduces the error rate 85% in both data science and software engineering. The improvement in the BERT based hybrid model is because BERT can understand contexts and can differentiate between:
"Python for data analysis and statistical modeling" (Data Science)
"Python for API development and systems engineering" (Software Engineering)
This semantic ambiguity is important. The hybrid can do a little more than keyword matching, it understands professional context. The confusion matrix shows that BERT based models reduced disambiguation between disciplines. The error rate between Data Science and Software Engineering when mapping to one or the other dropped by more than 85%. The error rate between Data Science and Software Engineering, compared to the TF-IDF baseline.
Table 3: The comparison of CV’s classification models according to performance metrics
Model | Accuracy | Macro F1 | Precision | Recall |
TF-IDF + SVM | 85.20% | 83.20% | 83.40% | 82.00% |
BERT (Fine-tuned) | 94.20% | 91.90% | 92.30% | 91.50% |
Hybrid (Proposed) | 94.90% | 92.90% | 93.40% | 92.60% |
Explainability with SHAP
Clarity of these outcomes is important in AI, especially for hiring. A feature called SHAP was included that breaks down every choice made by system, working with every type of model built. By inserting the explanation layers, what we have done is change the tech from being a gadget to who cares to something useful for the one who hires. What has resulted is a way for recruiters to see how the decisions are actually being made, by immersing the XAI layer under the hood of the knowledge worker ranking system, Peeking under the hood with SHAP gives hiring managers insight into which keywords drive the job rankings transparently (Figure 4).

Figure 4: SHAP Word Importance, for Data Science Resume
SHAP explains how the model is influenced by words; keywords are the keys to unlocking how it works. “Data Science” resumes would contain certain words that stand out-TensorFlow, statistical modeling, machine learning. Words in Functional Areas, say sales or customer service, would be virtually absent. This is because the non-technical weight is diminished. What’s left is what is critical-excesses are filtered away, emphasizing core competencies. This is what the model gives you directly, this is what helps us in fairness test. Recruiters feel empowered. This is seeing the results of intelligent craft.
A hybrid of the converter-based and precise-named-entity-classification approaches gives a speedy answer for job applicants and gets 94.9% accuracy on a real-world dataset. The model is said to be ready for production.
Both RoBERTa and DistilBERT models performed well and after reviewing the results, I selected BERT. BERT strikes an ideal balance between accuracy and computational cost, a crucial factor for real-world applicant tracking system applications.
Acknowledgement
I am pleased to present this research entitled "Use Recommendation Systems to Analyse Resumes Using Deep Learning Analysis of a Resume Classification dataset" and I express my deep gratitude to everyone who dedicated their valuable time and provided guidance and support when I needed it most. It is a great honor for me to conduct this work in the esteemed Department of Computer Science, College of Computer Science and Mathematics, Tikrit University, Iraq.
Gupta, S.P.A.E.R. Proceedings of International Conference on AI and Financial Innovation. Vol. 446, Springer Nature Singapore, 2025. https://doi.org/10.1007/978-981-96-7269-1.
Akhtar, Nikhat et al. “AI-Driven Intelligent Resume Recommendation Engine.” International Journal of Scientific Research in Science, Engineering and Technology, vol. 12, no. 3, June 2025, pp. 1141-1155. https://doi.org/10.32628/ ijsrset2512145.
Abbas, A.F. and M.Z. Abdullah. “Design and Implementation of Tracking a User’s Behavior in a Smart Home.” IOP Conference Series: Materials Science and Engineering, vol. 1094, no. 1, February 2021, p. 012008. https://doi.org/ 10.1088/1757-899x/1094/1/012008.
Alabi, M. “AI-Powered Product Recommendation Systems: Personalizing Customer Experiences and Increasing Sales.” 2024.
Zhou, C. et al. “Optimal Recommendation Strategies for AI-Powered E-Commerce Platforms: A Study of Duopoly Manufacturers and Market Competition.” Journal of Theoretical and Applied Electronic Commerce Research, vol. 18, no. 2, June 2023, pp. 1086-1106. https://doi.org/ 10.3390/jtaer18020055.
Zielnicki, K. et al. “The Value of Personalized Recommendations: Evidence from Netflix.” November 2025. arXiv. https://doi.org/abs/2511.07280.
Abdulateef, S.K. “Evolutionary Optimization of Geometrical Image Contour Detection.” International Journal of Intelligent Engineering and Systems, vol. 15, no. 2, April 2022, pp. 287-297. https://doi.org/10.22266/ijies2022.04 30.26.
Devlin, J. et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” GitHub, https://github.com/tensorflow/tensor2tensor.
Qaiser, S. et al. “Text Mining: Use of TF-IDF to Examine the Relevance of Words to Documents Text Mining.” 2018.
Zheng, D. et al. “Analyses of Multiyear Statewide Secondary Crash Data and Automatic Crash Report Reviewing.” Transportation Research Record, vol. 2514, 2015, pp. 117-128. https://doi.org/10.3141/2514-13.
AL-Qassem, A.H. et al. “Leading Talent Management: Empirical Investigation on Applicant Tracking System (ATS) on e-Recruitment Performance.” 2023 International Conference on Business Analytics for Technology and Security (ICBATS), IEEE, March 2023, pp. 1-5. https://doi.org/ 10.1109/ICBATS57792.2023.10111172.
Smith, M.R. et al. “Mind the Gap: On Bridging the Semantic Gap between Machine Learning and Information Security.” May 2020. arXiv. https://doi.org/abs/2005.01800.
Zhang, L. “Features Extraction Based on Naive Bayes Algorithm and TF-IDF for News Classification.” PLoS One, vol. 20, no. 7, July 2025. https://doi.org/10.1371/journal. pone.0327347.
Reimers, N. and I. Gurevych. “Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks.” Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, 2019, pp. 3980-3990. https://doi. org/10.18653/v1/D19-1410.
Dilshan, B.A.T. and P.P.G.D. Asanka. “Enhancing Resume Analysis: Leveraging Natural Language Processing and Machine Learning for Automated Resume Screening Using KSA Parameters.” 2025 5th International Conference on Advanced Research in Computing (ICARC), IEEE, February 2025, pp. 1-6. https://doi.org/10.1109/ICARC64760. 2025.10963312.
Antoun, W. et al. “AraBERT: Transformer-based Model for Arabic Language Understanding.” March 2021. arXiv. https://doi.org/abs/2003.00104.
Buolamwini, J. “Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification.” 2018.
Chavan, P.R. et al. “Enhancing Recruitment Efficiency: An Advanced Applicant Tracking System (ATS).” Industrial Management Advances, vol. 2, no. 1, July 2024, p. 6373. https://doi.org/10.59429/ima.v2i1.6373.
Sohail, S.S. et al. “Classifications of Recommender Systems: A Review.” Eastern Macedonia and Thrace Institute of Technology, 2017. https://doi.org/10.25103/jestr.104.18.
Li, C. et al. “Deep Learning-Based Recommendation System: Systematic Review and Classification.” IEEE Access, vol. 11, 2023, pp. 113790-113835. https://doi.org/10.1109/ ACCESS.2023.3323353.
Enríquez, J.G. et al. “Recommendation and Classification Systems: A Systematic Mapping Study.” Scientific Programming, vol. 2019, June 2019, pp. 1-18. https://doi. org/10.1155/2019/8043905.
Sonuga, Ayodele Emmanuel et al. “End-to-end AI Pipeline Optimization: Benchmarking and Performance Enhancement Techniques for Recommendation Systems.” Global Journal of Research in Engineering and Technology, vol. 2, no. 1, September 2024, pp. 1-17. https://doi.org/ 10.58175/gjret.2024.2.1.0025.
Abdulateef, S.K. et al. “Feature Weighting for Parkinson’s Identification Using Single Hidden Layer Neural Network.” International Journal of Computing, July 2023, pp. 225-230. https://doi.org/10.47839/ijc.22.2.3092.
Hussein, M.M. et al. “Performance Evaluation of Different Deep Learning Architectures for Predicting Otitis Media with Effusion.” 2025 3rd International Conference on Business Analytics for Technology and Security (ICBATS), IEEE, May 2025, pp. 1-7. https://doi.org/10.1109/ICBATS 66542.2025.11258477.
