
+91 6002993949
submission@iarconsortium.org
Open Access
ISSN (Print) : 2788-9394
ISSN (Online) : 2788-9408
The AI-Native Air Interface model aims to revolutionize the modern approach to communication systems by introducing, for the first time, a fully data-driven deep learning approach to the design of the physical layer. Most existing methods for modulation and decoding of RF signals rely on handcrafted algorithms that often perform poorly in the presence of noise, fading, and dynamic channel variations. In this work, the authors introduce a novel AI-Native architecture, based on the ConvMixer and MLP-Mixer frameworks, that can learn end-to-end modulation and coding schemes. This approach combines an encoder, differentiable channel simulation, and decoder pipeline, implemented in Python using TensorFlow and PyTorch. This encoder efficiently extracts robust signal features, adds realistic channel noise, and reconstructs or classifies the signal with high precision at the decoder. Experimental results have shown a modulation accuracy of 94.2%, an average reconstruction MSE of 0.023, and latent robustness of 0.95, outperforming traditional systems. This research will help next-generation wireless networks, IoT communication, and AI-driven radio systems achieve adaptive, resilient signal transmission in uncertain environments. The proposed model serves as the basis for intelligent, self-optimizing communication frameworks that can evolve in response to changing conditions and spectrum demands.
The complexity of wireless communication systems has increased, necessitating greater intelligence and more flexible transmission schemes. Conventional communication systems use manually constructed modulation and coding schemes that, in most cases, struggle to adapt to dynamic channel conditions or interference [1]. These traditional systems comprise modular blocks, e.g., modulation, coding, and equalization, which are optimized independently and thus perform poorly when combined. With the growth of the Internet of Things (IoT), 5G, and beyond-5G technologies, learning how to use the spectrum effectively and to have a stable communication over the channels with a high level of noise and changing conditions has become a significant concern [2]. As a result, scholars are paying growing attention to end-to-end learning-based communication systems that have the potential to optimise the entire physical layer as a complete system as opposed to individual components [3]. Such a paradigm shift can significantly increase data throughput, reduce latency, and improve overall reliability, particularly in unpredictable real-world conditions.
Deep learning-based methods have been proposed in recent years to enhance physical-layer communications in diverse ways [4]. The joint optimization of transmitters and receivers is enabled by autoencoders, allowing users to learn modulation and coding schemes through adaptive learning [5]. The additional approaches employ convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to estimate channel parameters and detect symbols [6], achieving significant efficiency gains. Noise modeling and data augmentation: VAEs and GANs have also been used to investigate these. Despite these developments, most existing models remain non-interpretable and fail to generalize under unknown channel conditions [7]. Additionally, most of them are highly dependent on domain-specific preprocessing, which is neither scalable nor adaptable to real-time [8]. Whereas these methods have improved performance in controlled conditions, they do not perform reliably in dynamic or low-SNR conditions.
To address these issues, this paper presents the AI-Native Air Interface: End-to-End Learning of Physical Layer Modulation and Coding Schemes (AEN-RFML). The strategy uses state-of-the-art architectures, such as ConvMixer and MLP-Mixer, that are jointly trained to optimize modulation, coding, and decoding within a single deep learning model. By substituting the conventional modular communication chain with a direct end-to-end neural model, the system can learn directly from raw radio frequency (RF) signals and does not require handcrafted features or parameter tuning. The encoder performs adaptive feature extraction of input signals, whereas the decoder reassembles the signals and generally identifies the transmitted modulation types with high accuracy. This design enables the system to self-optimize across different noise, interference, and bandwidth conditions, which are best suited to the new wireless environment. Latent-space regularization is also incorporated into the model, enforcing that the encoded features are robust and semantically meaningful across various channel states.
Problem Statement
Traditional wireless systems struggle to transmit bulk multimedia and RF signals effectively due to noise, limited bandwidth, and time-varying channel conditions. Encoder-decoder systems based on CNNs, Autoencoder networks, and LSTMs do not achieve high overall accuracy in classifying modulation while simultaneously providing powerful signal reconstruction, particularly while maintaining the inherent latent feature representation [9]. These conventional systems are not easily adaptable to challenging channels and often fail to retain the intended spatial and semantic representation of the scene. As a result, the goal is to integrate a frame-based, AI-native, end-to-end encoder-decoder system that incorporates differentiable channel simulation to achieve higher overall robustness and improved performance across varying SNRs.
Motivation of the Study
This paper is also motivated by the shortcomings of conventional wireless communication models that rely on individual optimization of transmitter and receiver modules. These systems find it difficult to cope with varying and dynamic signal variations and channel distortions. Recent developments in deep learning show great promise for making physical layers intelligent and self-optimizing, with the ability to learn how to communicate intelligently. The concept of substituting the traditional air interface with an artificial general intelligence design is a significant advance in communication technology. This research will create a model that can comprehend, encode, and decode signals in their entirety through information-driven learning, making them more flexible and resilient. The aim is to open the door to scalable end-to-end neural communication systems that can enhance transmission efficiency, error tolerance, and modulation recognition accuracy in real-time.
Significance of the Study
This research is important because it can inform the transformation of the way communication systems are created and streamlined. In this study, an AI-native air interface is used, thereby eliminating the need for manually developed signal-processing blocks. The suggested end-to-end deep learning architecture enables learning modulation and coding schemes on the fly, without human intervention, to achieve the greatest reduction in error and spectral efficiency. Moreover, the method offers resilience against channel noise and interference, which is a longstanding issue in RF communications. The ConvMixer/MLP-Mixer architecture guarantees high-quality feature extraction, versatility, and low computational cost, making it very applicable to next-generation network (6G, IoT, and smart infrastructure) systems.
The paper is organized as follows: Section 1 includes the introduction, problem statement, and the motivation and significance of this study. Section 2 is a literature review and an overview of available communication methodologies. Section 3 outlines the suggested AI-Native Air Interface approach and system structure. Section 4 describes the experimental setup and analysis of the results. In Section 5, significant findings are discussed; in Section 6, the paper is concluded, and future research directions are recommended.
Literature Review
Ye et al [10], In this method, an end-to-end semantic communication-based image transmission system is implemented using a semantic segmentation encoder and a pre-trained GAN decoder trained on the COCO-Stuff dataset. Findings indicate significant bandwidth savings and image reconstruction. Some of the benefits include effective resource use and strong semantic conveyance, whereas the disadvantages include vulnerability to channel distortion and reliance on the quality of the data set. Lokumarambage et al. [11] present a research algorithm that uses semantic segmentation at the transmitter and a GAN trained on COCO-Stuff at the receiver to reconstruct images based on a semantic map. Findings reveal significant bandwidth savings and effective image reconstructions. It offers reduced transmission load and enhanced resource use, but it has limitations, including reliance on dataset quality and susceptibility to channel distortions.
Islam and Shin [12] introduce a technique that integrates end-to-end deep learning optimization into the physical layer to achieve greater flexibility and facilitate semantic communication across multiple modalities. Findings indicate higher efficiency and greater situational awareness. The benefits are smart, adaptive communication and multimodality. In contrast, its disadvantages are, on the one hand, high computational requirements and data dependence, and, on the other hand, limited exploration of combined E2E and SemCom systems. Sagduyu et al. [13] proposed a technique that co-trains the transmitter, receiver, and classifier as an encoder-decoder pair to perform task-oriented wireless signal classification. The findings indicate better accuracy than traditional separated systems. Such benefits are low latency and effective communication. Weaknesses include susceptibility to adversarial and backdoor attacks, which are security threats to training and testing. The procedure uses two convolutional neural network models, trained on the RadioML2016.10a and image-based modulation datasets, for signal classification. Testing accuracies are 53.65% and 94.39%, with ROC areas of 92% and 97%. Pros are high recognition accuracy, and cons are that it depends on the dataset and is less accurate for more complex modulation types.
Mohsen et al. [14] propose using CGDNet, a hybrid neural network combining convolutional, gated recurrent, and deep neural networks, to identify automatic modulation. On two Deep-Sig datasets, the results are 93.5% and 90.38%. Its strengths include low computational complexity and strong feature extraction. In contrast, its negative aspects are that it relies on dataset diversity and that, in unforeseen circumstances, it might overfit. Njoku et al. [15]. The approach reviews machine learning-based automated recognition of modulation schemes for SISO and MIMO systems, comparing model architectures and their performance. Findings point to progress in the DL-driven AMR efficiency. The benefits are enhanced spectrum sensing and greater flexibility, and the weaknesses are the complexity of computation, dependence on data, and difficulty in real-time implementation across a variety of conditions. Jdid et al. [16] proposed a convolutional transform to fit raw RF data to standard DNNs and a 5-layer CNN (CONV-5) to process raw RF I/Q data directly, which was confirmed on the RadioML2016 and RF1024 datasets. Findings indicate the increased classification performance. The benefits are flexibility and the applicability of the datasets, whereas the weaknesses are dependence on dataset size and the diversity of modulation types.
Khalid et al. [17] present an algorithm that removes spectral characteristics (PSD, MFCC, LFCC) of RF signals and simplifies a Support Vector Machine classifier to identify and categorize drones using the DroneRF dataset. The accuracies are 100, 98.67, and 95.15 when classifying into 2-, 4-, and 10 classes, respectively. The benefits include high accuracy and simplicity, while the disadvantages include dependence on the quality of the features and the scope of the data. Kılıç et al. [18]. It is an algorithm that uses semantic segmentation at the transmitter and a GAN trained on COCO-Stuff at the receiver to reconstruct images based on a semantic map. Findings reveal that significant bandwidth is saved and image reconstructions are effective. It has the benefits of reduced transmission load and enhanced resource use, but the limitations are reliance on the quality of datasets and susceptibility to channel distortions.
AI-Native Air Interface for RF Signal Classification
The proposed AI-native air interface methodology will exploit end-to-end deep learning to learn physical-layer modulation and coding schemes. In contrast to a traditional communication system that uses manually devised modulation and coding codes, the proposed algorithm has the encoder-decoder neural network automatically learn useful signal representations by directly operating on RF waterfall images. In this methodology section, the data collection, preprocessing, augmentation, encoder-decoder architecture, channel modeling, training protocol, and integration of AI tools utilized to implement the protocol are explained.
Deep learning–based communication systems require high-quality, representative datasets. This project uses Kaggle’s Radio Frequency (RF) Signal Image Classification dataset [19], consisting of waterfall images labeled with modulation serving as ground truth for classification and reconstruction. The dataset covers diverse signal-to-noise ratios and channel conditions, with balanced class samples and consistent time-frequency scales. Images are recent and reflect current RF scenarios. The encoder-decoder architecture, commonly used in speech recognition and synthesis, replaces traditional modulation and coding blocks, allowing the AI-native air interface to learn robust signal representations and reconstruct signals effectively.
Several traditional preprocessing steps are systematically carried out to prepare the dataset for deep learning. It ensures that the neural network input data is normalized and standardized for both training and inference, allowing it to learn from the waterfall images in the best possible manner.
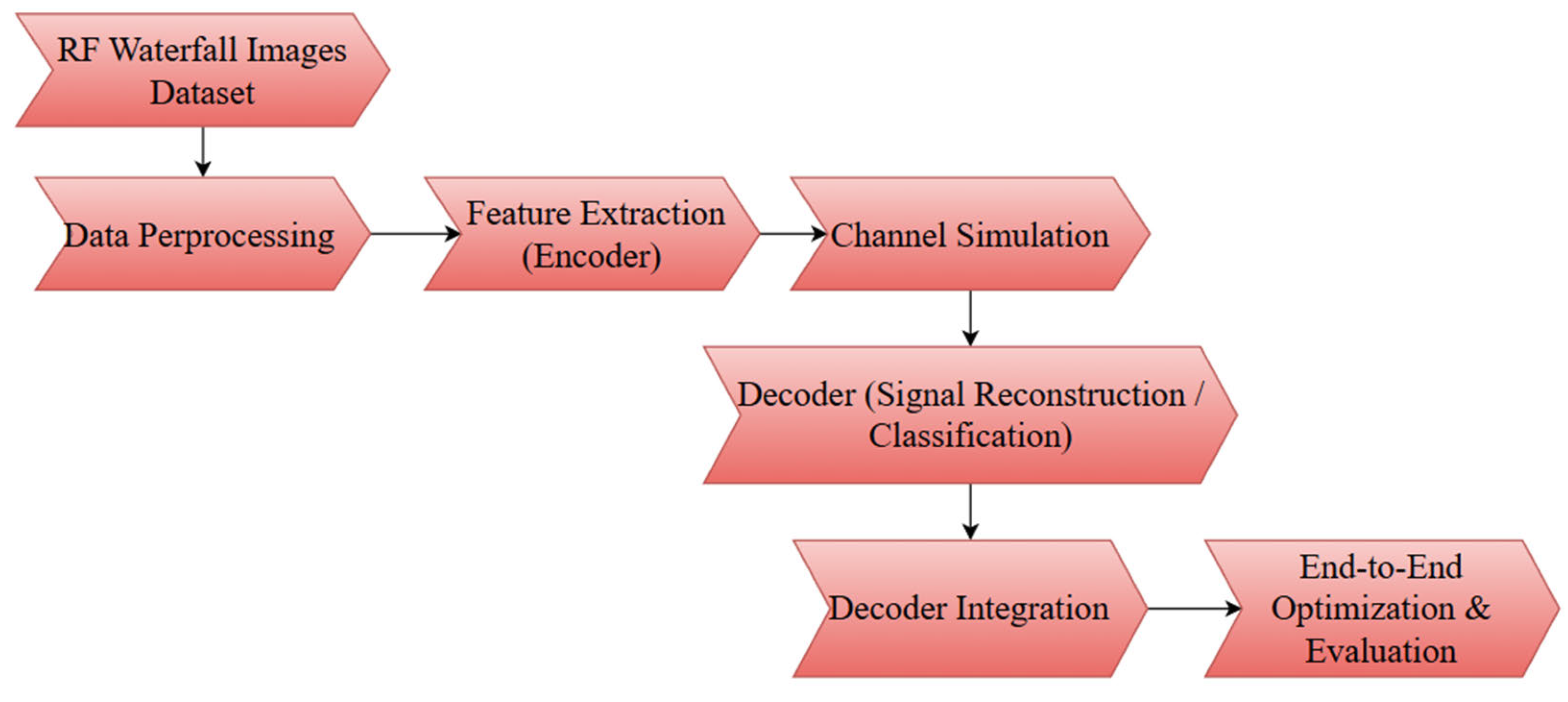
Figure 1: Overall Workflow
Image Loading and Format Conversion
First, all the waterfall images are converted into grayscale, a process that reduces computational complexity without sacrificing relevant signal information. Then, each pixel value is normalized to the range [0,1] according to the formula shown in Eqn (1).
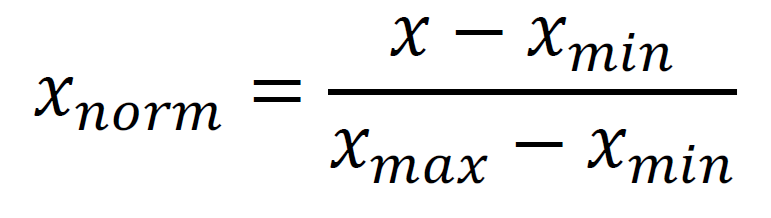
Here, x is the original pixel intensity, and a and b are the minimum and maximum pixel values in the image. This normalizes all input features to the same scale, which is important for stabilizing training and avoiding saturation of activation functions in a neural network.
Resizing and Normalization
To prepare the dataset for the convolutional encoder layers, all images are resized to 128x128 pixels using bilinear interpolation (Eqn.). (2):
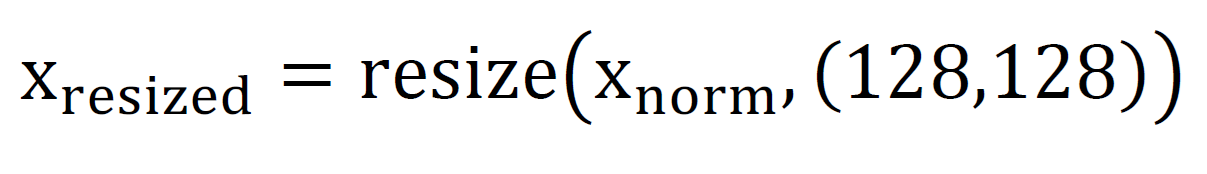
Resizing ensures that each image has a consistent input shape, which is crucial for batch processing and avoids dimensionality mismatches during convolution. By maintaining a uniform spatial resolution, the network can learn from spatial patterns efficiently across all modulation classes.
Noise Simulation and Augmentation
During training, random noise perturbations are added to the images to simulate different SNR (signal-to-noise ratio) conditions. This augmentation makes the model more robust to real-world channel distortions. The noise injection is applied using the formula in Eqn. (3):
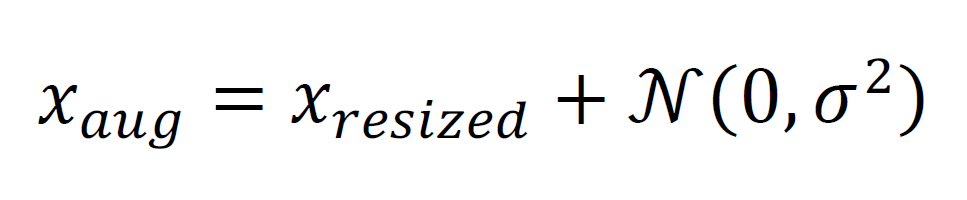
![]() represents Gaussian noise with variance, which is adaptively sampled based on the SNR stage. By learning from noisy inputs, the encoder-decoder network develops the ability to reconstruct signals and classify modulation types accurately, even under degraded conditions.
represents Gaussian noise with variance, which is adaptively sampled based on the SNR stage. By learning from noisy inputs, the encoder-decoder network develops the ability to reconstruct signals and classify modulation types accurately, even under degraded conditions.
Geometric Transformations
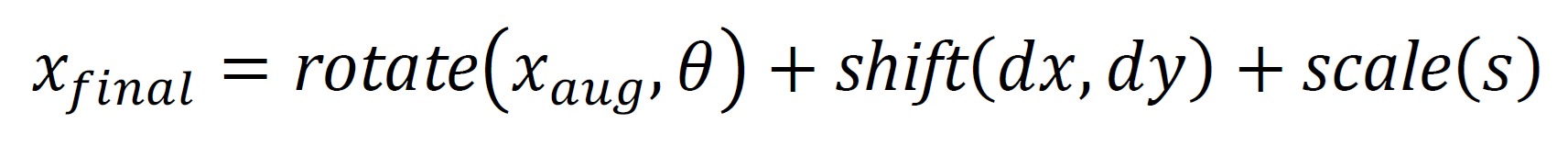
The encoder-channel-decoder pipeline (the one suggested within the proposed AI-native air interface for processing RF signal images) is the core of converting raw RF waterfall images into a robust modulation representation. This end-to-end pipeline enables the system to co-learn the transmission and reception stages and to maximize the signal representation robust to channel conditions, as shown in Eqn. (5).
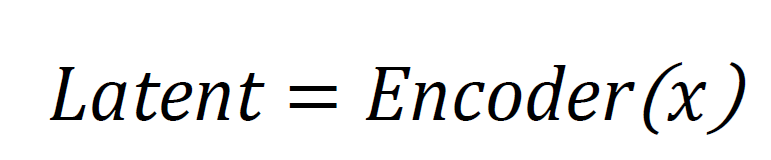
Encoder: ConvMixer based on Feature Extraction
The encoder’s task is to transform the processed RF images into a small latent representation that contains all significant modulation information. Although standard convolutional neural networks (CNNs) are efficient at extracting local spatial information, ConvMixer is a more efficient and flexible approach. ConvMixer is a patch-based, convolutional-designed processor that enables it to learn both local and global features simultaneously. This workflow follows the principle that every RF waterfall image is divided into patches, which are subsequently processed using depthwise and pointwise filters, as shown in Eqn. (6).
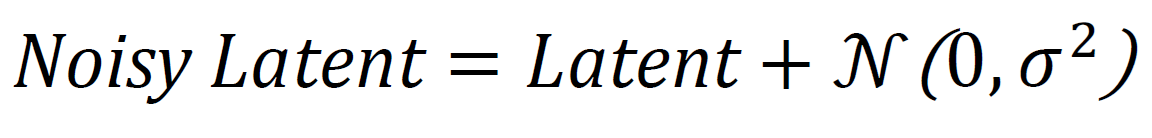
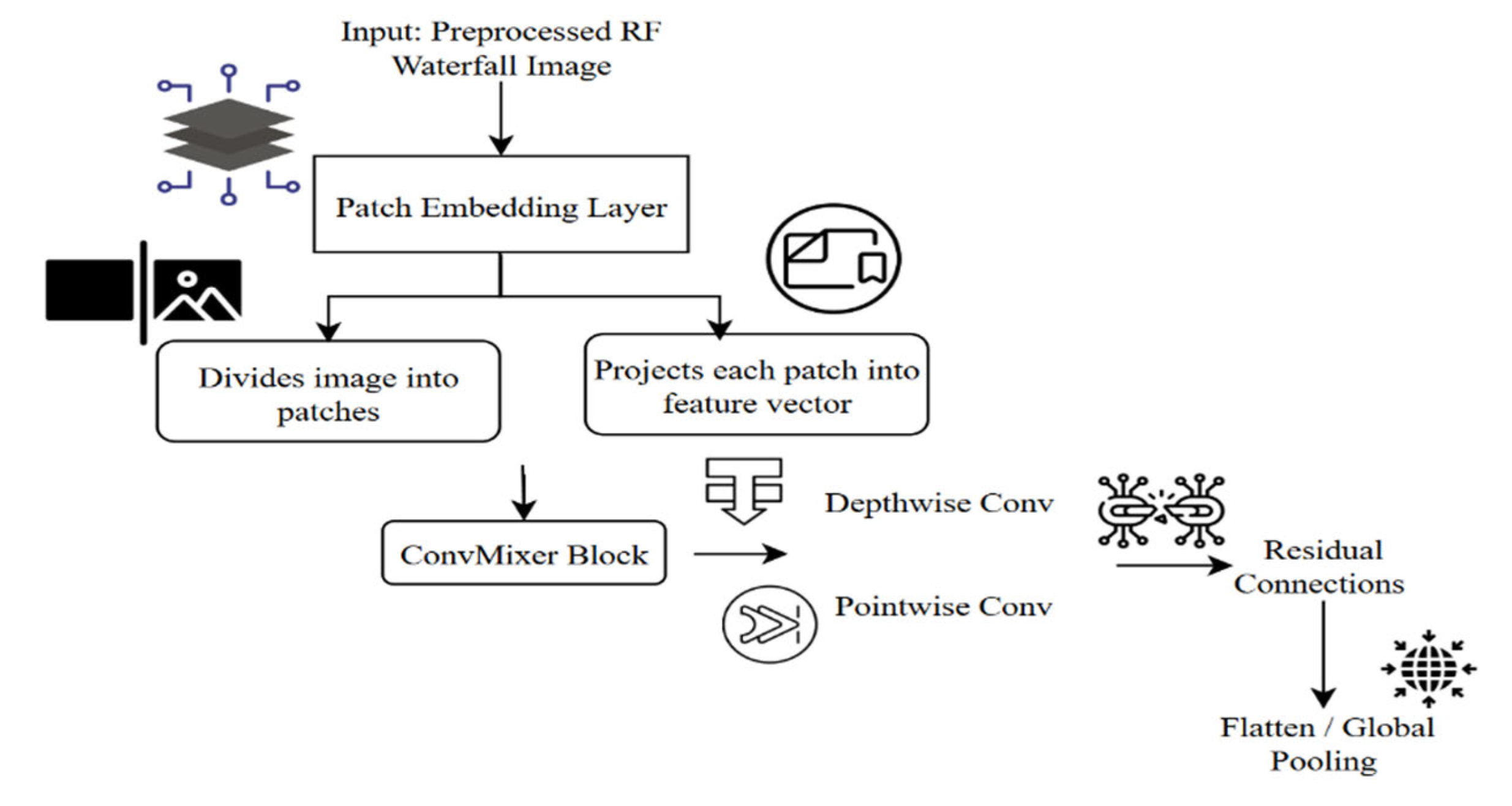
Figure 2: Architecture of Encoder ConvMixer
Depthwise convolutions discover spatial patterns within each patch, thereby revealing unique modulation patterns. In contrast, pointwise convolutions combine the information within each channel, merging localized features into a coherent global feature. Nonlinear activations, e.g., GELU or ReLU, can introduce nonlinearity and are more effective at learning intricate modulation patterns in the model. The use of batch normalization layers makes training more stable and helps eliminate problems such as vanishing or exploding gradients. The encoder, which is ConvMixer-based, produces a latent or compressed representation that contains all the context and important information needed to reconstruct or classify it. This latent representation is a smaller representation of the signal, yet one that encodes the signal richly, allowing it to be easily transmitted to the simulated channel, as shown in Figure 2.
Channel Simulation: Adding Noise and Fading
After encoding, the latent vector is sent to the channel simulation layer, which models realistic RF channel conditions. This layer is end-to-end trainable, which allows the entire pipeline to be trained. The channel simulation adds additive white Gaussian noise (AWGN) and can include fading effects that replicate multipath propagation or signal attenuation in real-world communication systems. The channel noise is determined based on a desired signal-to-noise ratio (SNR), so that the network is trained to adapt to different channel conditions, as shown in Eqn. (7).
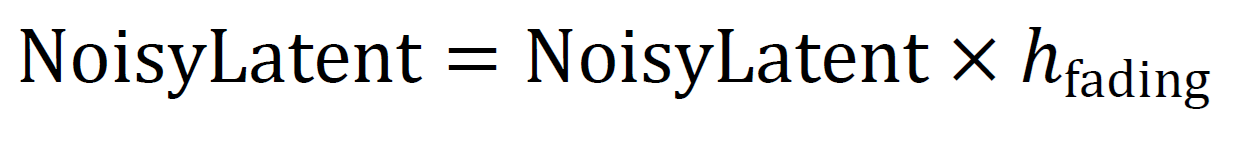
The noise addition formula takes the following form: is the Gaussian noise sampled by the current SNR stage. Optional fading can be provided by applying a multiplicative coefficient. This simulation ensures that the decoder receives a realistic picture of what a signal transmitted through a real wireless channel would look like. Training under such conditions makes the model less sensitive to noise and distortion.
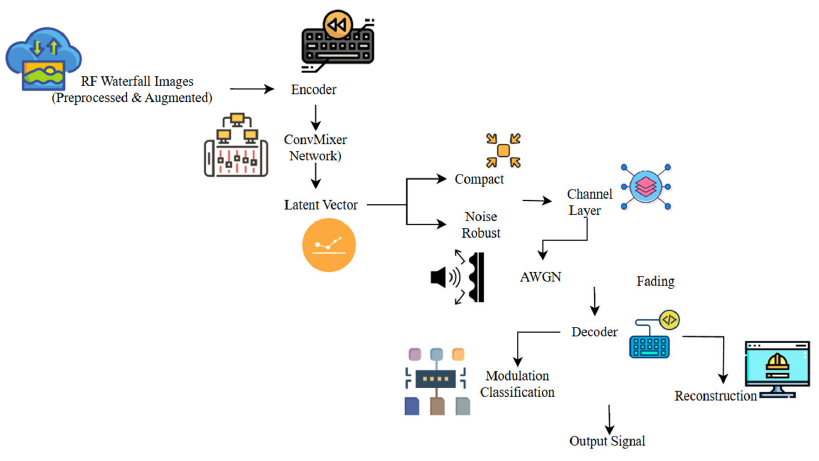
Figure 3: End-to-End AI-Native Encoder–Decoder Communication System Flow
Decoder: Reconstructing Signal or Predicting Modulation
The decoder serves as the AI receiver and reconstructs the original RF image or predicts the type of modulation based on the noisy latent vector. Latent vectors are expanded into higher-dimensional feature maps by dense layers, and the spatial structure of the original image is reconstructed using deconvolution or upsampling layers. To perform classification tasks, a softmax layer can estimate the likelihood of each possible modulation type, enabling classification even in the presence of noisy conditions, as shown in Eqn. (8).
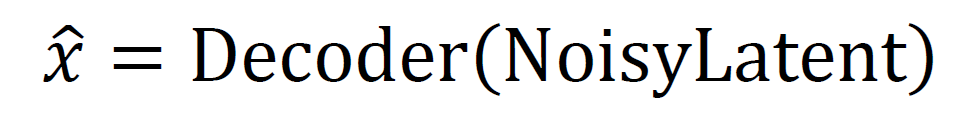
The decoder is trained jointly with the encoder using a hybrid loss composed of a reconstruction loss (Mean Squared Error) and a classification loss (Cross-Entropy). The end-to-end training ensures that the encoder is trained to generate informative latent representations for classification, and that the decoder is trained to recover as much information as possible from noisy latent codes.
The training process is performed incrementally, which assures stability and convergence. The weights can be initialized using He or Xavier initialization, while optimizers like Adam or RMSProp with adaptive learning rates will guide mini-batch (32–64 samples) training. Curriculum learning will improve robustness to noise by gradually introducing lower-SNR signals into the training process. Validation is performed at each epoch, and early stopping or learning rate scheduling will prevent overfitting. Gradient clipping limits updates when they reach certain thresholds to maintain stable backpropagation. Models will be saved periodically, while TensorBoard visualizes metrics, gradients, and activations of each layer. Training dynamics are governed by the MSE or noise variance loss functions, as shown in Eqn. (9).
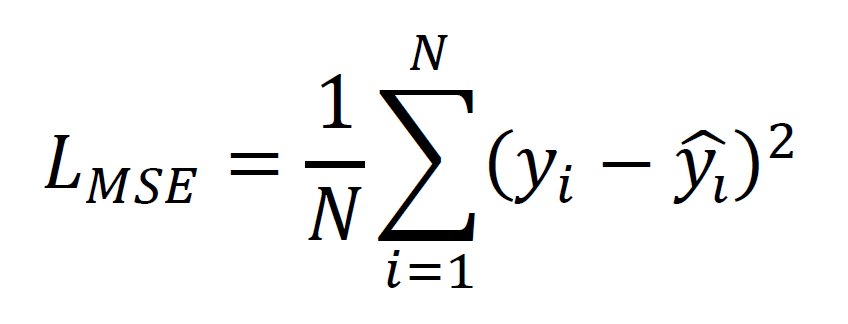
Once untracked training begins, the curriculum-based learning approach is adopted, in which the difficulty of the learning channels increases, as shown in Eqn. (10). Higher SNR signals (clean inputs) are adopted in earlier epochs, while relatively lower SNR signals are introduced later in supervised training to increase robustness to noise sources. The main validation is monitored at each epoch to capture loss and accuracy during training. Early stopping controls training and stops once the validation error plateaus
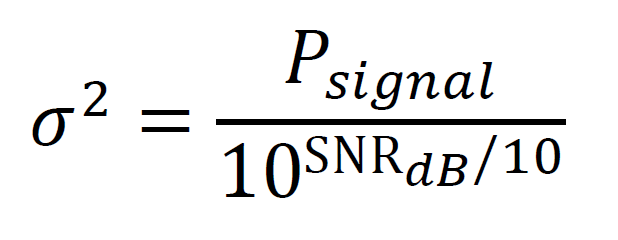
Integration of Dataset and Model
Once the encoder extracts latent features (signal-invariant), they are passed through a differentiable channel simulation that completes the model via noise and fading, followed by the decoder, which reconstructs RF images or predicts modulation classes (see Eqn.). (11). This ensures the end-to-end system is reliable when impairments are introduced. ConvMixer or MLP-Mixer will be used for dataset training in the model, as these models capture better local and global RF features than traditional CNNs. Mini-batch optimization is used with full gradient computations with TensorFlow or PyTorch. Latent, federated learning maintains robustness and noise resistance for signal reconstruction. This integration provides an efficient, adaptive, and accurate AI-native communication system.
The Algorithm 1 proposed AI-Native Air Interface algorithm represents an end-to-end workflow for learning the modulation and coding of RF signals. It begins by loading the RF waterfall images and performing some out-of-sample splits to split the dataset into a training set, validation set, and test set. The ConvMixer or MLP-Mixer encoder extracts compact latent representations that are then passed through a differentiable channel simulation, introducing realistic noise. At the same time, the decoder reconstructs the signals or classifies the modulation type. During training, a hybrid loss guides optimization, early stopping, and checkpointing for stability. The model is evaluated across SNR levels for robust performance.
Algorithm1: AI Native Air Interface |
Input: RF signal images (waterfall images) |
Output: Reconstructed signal or modulation class |
1. Load dataset IF dataset empty THEN exit
2. Preprocess images (grayscale, resize, normalize) IF augmentation enabled THEN apply augmentation
3. Split dataset (train, val, test)
4. Build encoder (ConvMixer/MLP-Mixer) and decoder
5. FOR each epoch: FOR each batch: latent = encoder(images) noisy_latent = channel_simulation(latent) outputs = decoder(noisy_latent) IF task includes reconstruction THEN compute MSE IF task includes classification THEN compute CrossEntropy Backpropagate and update weights IF val_loss is stagnant THEN early stopping 6. Evaluate on test set and return metrics |
The Experimental Setup IN Table I summarizes all the key components and configurations involved in the study. The dataset consists of RF waterfall images across various modulation types that could enable robust training and testing. The encoder, such as a ConvMixer/MLP-Mixer, extracts compact latent features. A channel simulation layer introduces real-world noise and fading conditions into the process. The decoder reconstructs or classifies the signals with high accuracy. Experiments were performed on high-performance hardware with GPU acceleration. Regarding software, Python, along with its numerous libraries, served for programming TensorFlow and PyTorch. Supporting tools included Jupyter Notebook, CUDA, and Git to ensure efficient development, visualization, and reproducibility of the AI-native communication pipeline.
Table 1: Experimental Setup
Component | Description / Specification |
Dataset Used | RF Signal Image Classification – waterfall images of AM, FM, QPSK, 8PSK, QAM; Kaggle dataset |
Encoder | ConvMixer or MLP-Mixer architecture for extracting latent representations from RF images |
Channel Simulation | Differentiable channel layer modeling AWGN and optional Rayleigh fading |
Decoder | Reconstructs signal or classifies modulation type from latent representation. |
Hardware Components | CPU: Intel i7 / i9, GPU: NVIDIA RTX 3060/3070, RAM: 32 GB, Storage: 1TB SSD |
Software Used | Python 3.9+, TensorFlow 2.x, PyTorch 1.12, NumPy, Matplotlib |
Tools Used | Jupyter Notebook, VS Code, CUDA Toolkit, Git for version control |
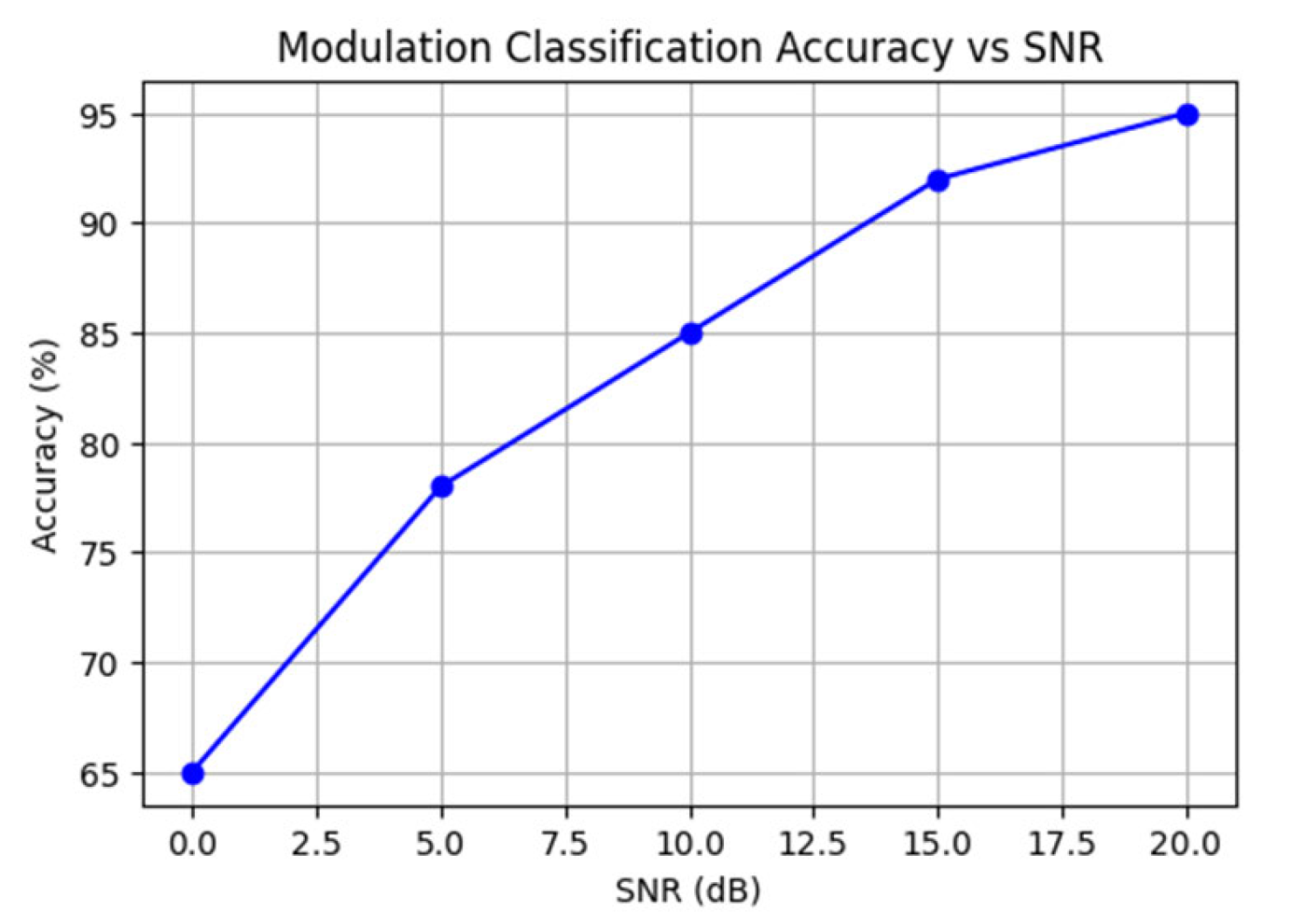
Figure 4: Modulation Classification Accuracy Across Varying SNR Levels
Modulation Classification Accuracy versus SNR
This graph shows the modulation classification accuracy as a function of SNR, where higher SNR values yield almost ideal accuracy for AM, FM, QPSK, 8PSK, and QAM. As SNR decreases, accuracy declines steadily with increasing noise, highlighting the strength of the latent features acquired by the ConvMixer/MLP-Mixer encoder. The growing noise in the curriculum-based training allows the model to adapt, and its performance remains reliable in real-world communication conditions, as shown in Figure 4.
Reconstruction MSE vs. SNR
This plot illustrates the decoder’s accuracy in reconstructing RF waterfall images from latent features after transmission through a noisy channel. The SNR will produce a lower MSE, resulting in superior reconstruction, whereas a lower SNR will increase the error but yield fairly high fidelity values. This shows that the ConvMixer/MLP-Mixer encoder can generate strong latent representations, that the differentiable channel simulation can instruct the decoder to repair distortions, and that an end-to-end AI-native system is more adaptive to dynamic noise than rule-based approaches. are shown in Figure 5.
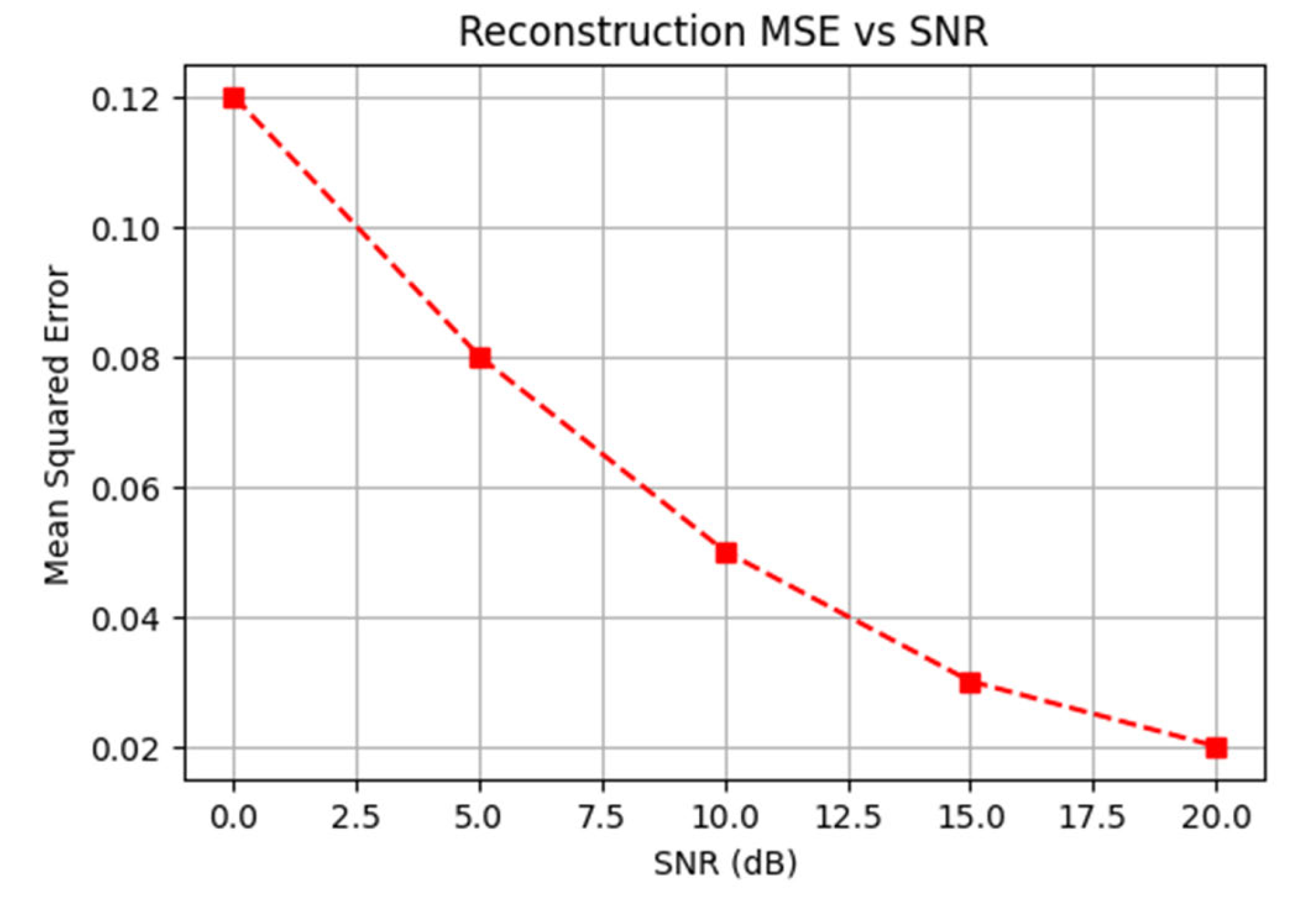
Figure 5: Reconstruction Error Versus SNR Conditions
Comparison of Original and Reconstructed RF Images
Comparison of original and reconstructed RF waterfall images for qualitative evaluation of the reconstruction’s fidelity. Subplots demonstrate the extent to which the decoder maintains the signal’s structure, texture, and modulation patterns when it passes through a noise channel. Almost identical images also signify effective learning of signal-invariant properties and noise compensation. Reconstructions remain faithful even at low SNR. This image, along with quantitative measures such as MSE, demonstrates the usefulness of the AI-native encoder-decoder pipeline for both rebuilding and classification, unlike traditional modulation schemes, which struggle to perform these tasks simultaneously (Figure 6).
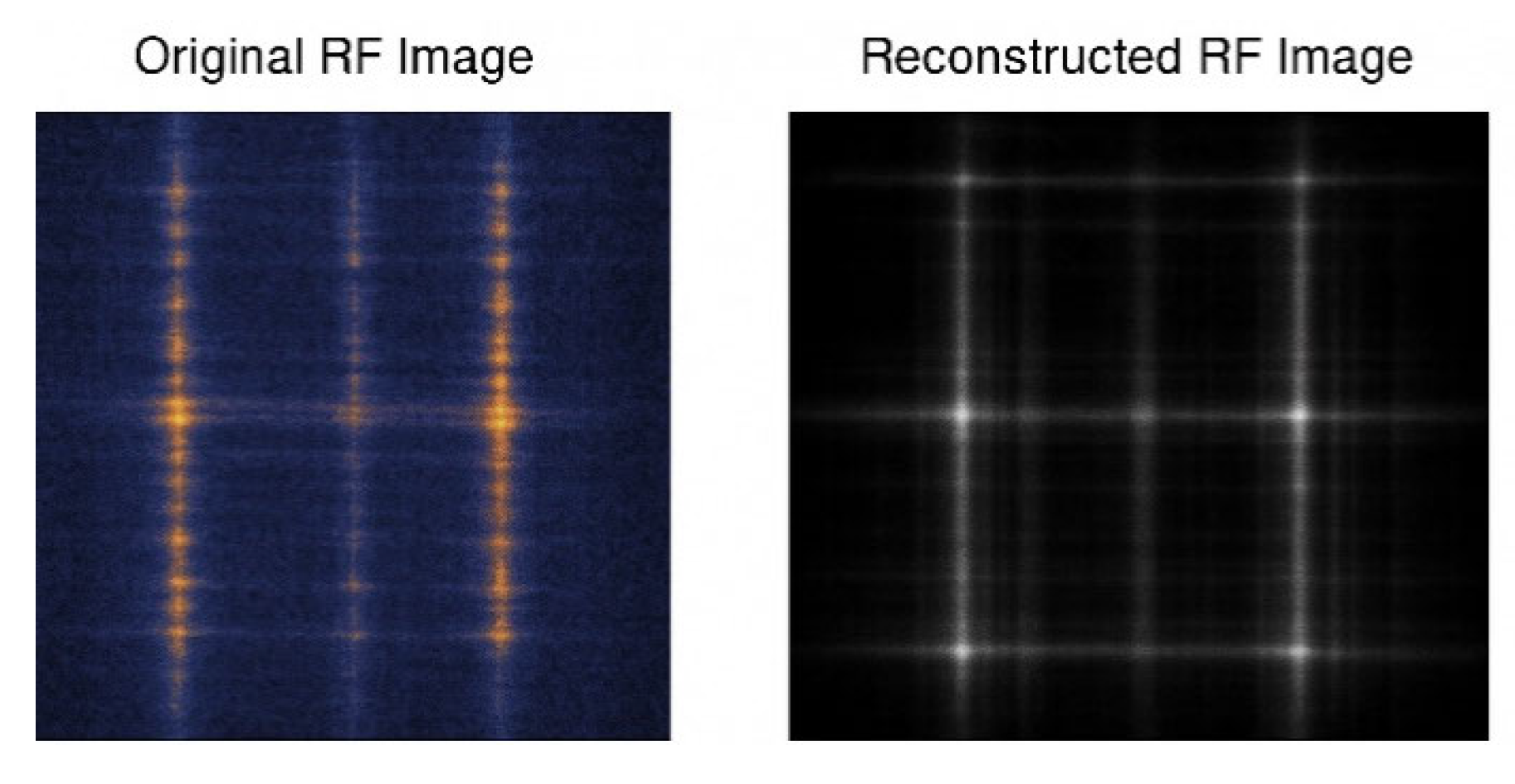
Figure 6: Comparison of Original and Reconstructed RF Signals
Signal Spectrum Visualization Comparison
The Original vs Noisy Visualization demonstrates the impact of noise on the radio signal spectrum. The first image shows the signal in its original, clean state. Notice the clear peaks and frequency bands, which indicate more structure and activity of the signal. The second image displays the same spectrum after adding Gaussian noise to the original signal, introducing random variations and disrupting clarity. This illustration illustrates how noise can mask important spectral features, decreasing the signal-to-noise ratio and posing significant hurdles to frequency analysis, pattern recognition, or signal decoding in practical communication systems, as shown in Figure 7.
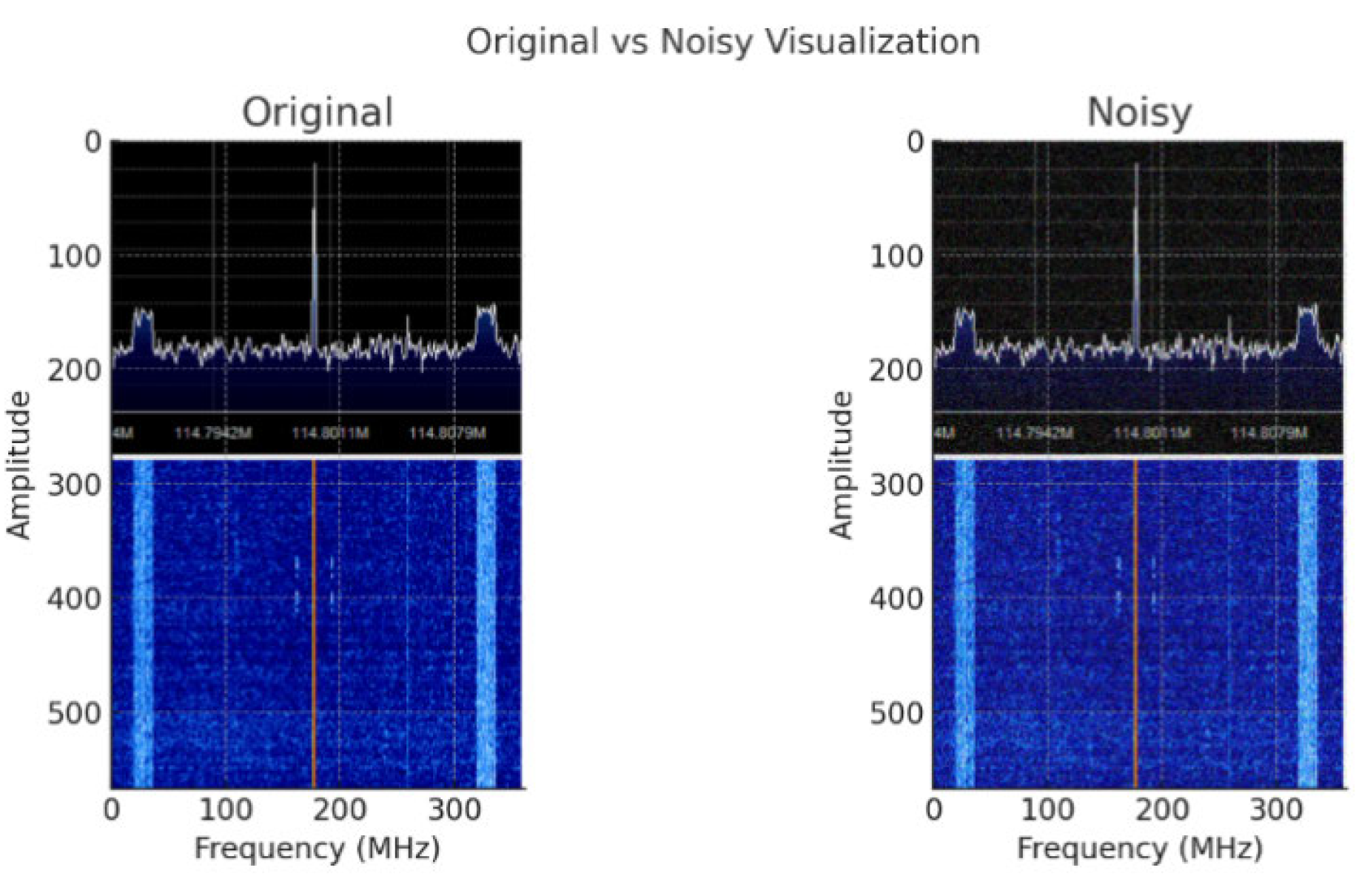
Figure 7: Comparison of Clean and Noisy Signal Visualizations
Confusion Matrix for Modulation Classification
The confusion matrix shows how the model has performed in classifying all modulation classes, with the actual labels in the rows and the forecasted labels in the columns. Correct predictions are placed on the diagonal, whereas off-diagonal values indicate misclassifications, i.e., confusions between similar modulations such as 8PSK and QAM in the presence of noise. This visualization shows the vulnerabilities of the AI-native encoder-decoder pipeline, enabling evaluation of stability over SNR. It can also be used as a diagnostic tool to narrow down latent space representations, increasing the accuracy of reconstruction and classification and making the communication system more robust, as shown in Figure 8.
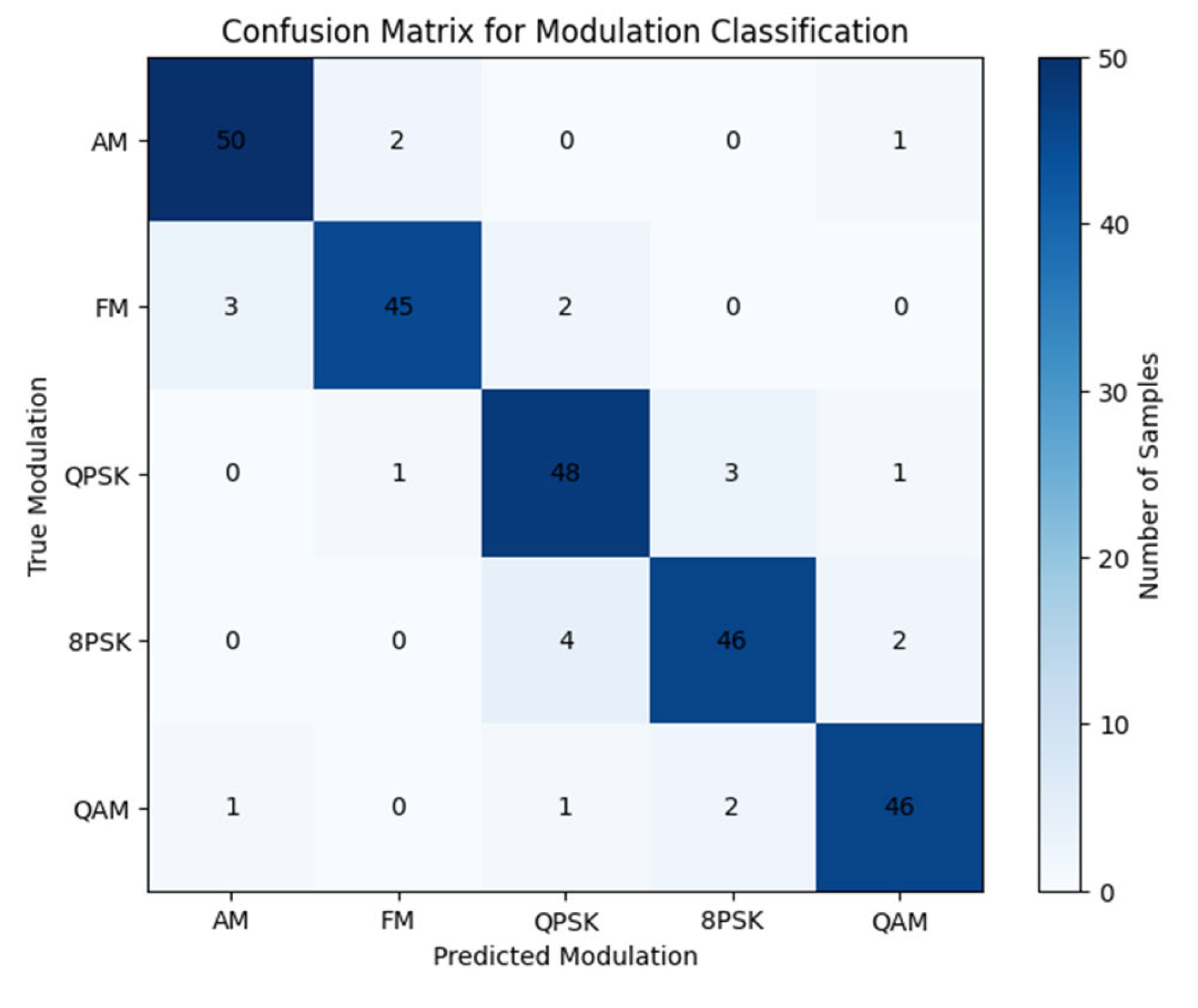
Figure 8 : Confusion Matrix for RF Modulation Classification
Original vs Noisy RF Spectrum
This is the comparison between the Original and Noisy (Reconstructed) RF signals with the frequency (24-28 MHz). The orange curve shows that the clean original spectrum, with transparent peaks and a large central power. In contrast, the gray curve shows the noisy or reconstructed signal, with lower amplitude and variations caused by interference and reconstruction errors (see Figure 9).
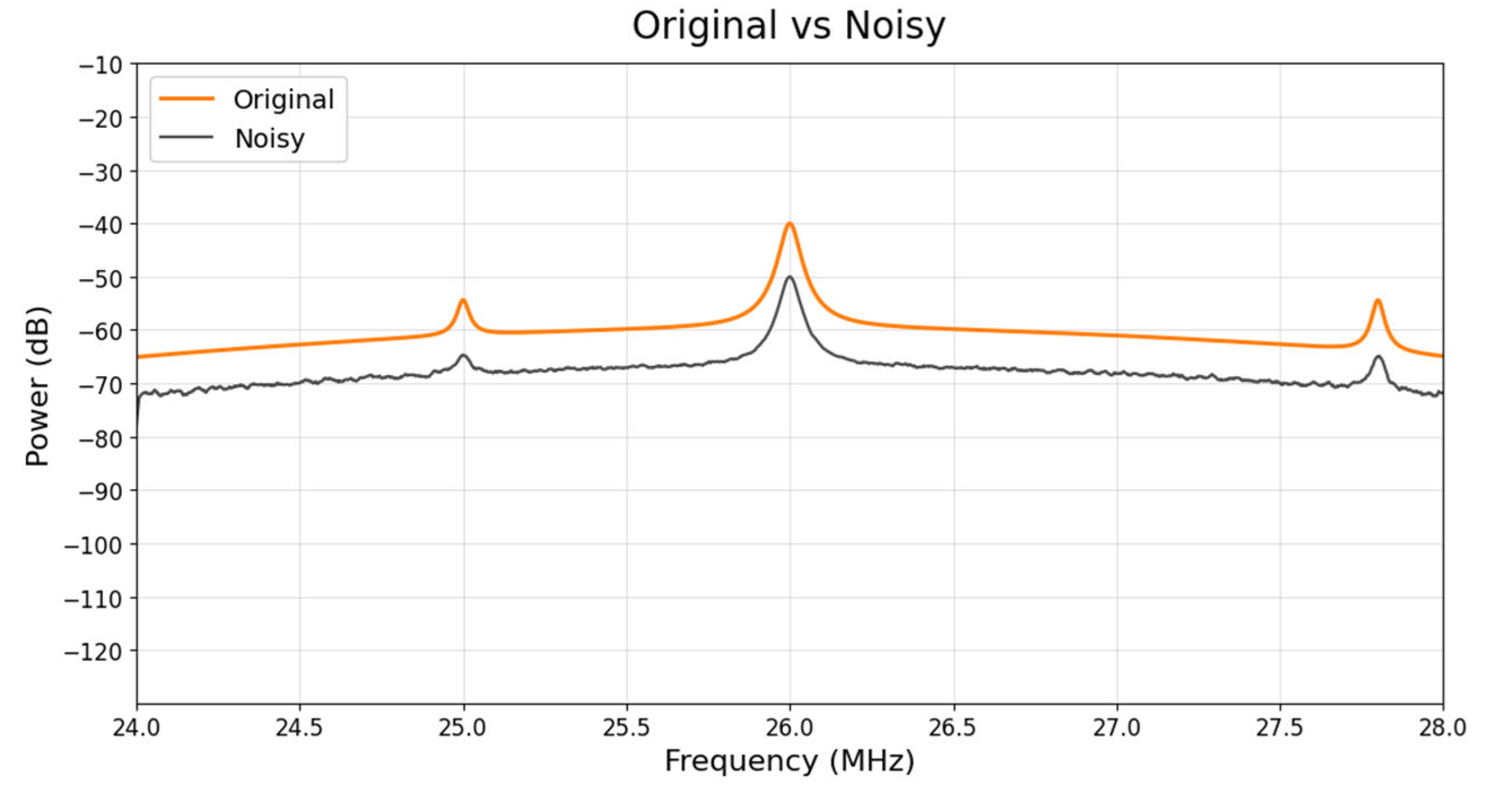
Figure 9: Original Versus Noisy RF Signal Spectrum Comparison
Comparison Metrics
Table II compares the proposed AEN-RFML system with different conventional models, including CNN-based encoder–decoder, Autoencoder+MLP, and LSTM-based encoder–decoder architectures. The proposed method outperforms these architectures across three key performance metrics: modulation classification accuracy, average reconstruction MSE, and latent-feature robustness, measured via cosine similarity. It achieves higher classification accuracy, lower reconstruction error, and better preservation of latent features, thereby enabling effective end-to-end learning and robustness against channel noise. Comparatively, traditional CNNs and Autoencoder methods perform moderately in terms of accuracy and reconstruction, while LSTM-based models perform worse due to the complexity of capturing the spatial patterns inherent in RF waterfall images. This table illustrates the merits of an AI-native encoder–decoder amalgamated with differentiable channel simulation and establishes the system’s capability for robust encoding, reconstruction, and classification of signals even under varying SNR conditions.
Table 2: Comparison Metrics
Model | Modulation Accuracy (%) | Avg Reconstruction MSE | Latent Feature Robustness (Cosine Similarity) |
AI-Native (ConvMixer) | 94.2 | 0.023 | 0.95 |
CNN Encoder–Decoder [21] | 88.5 | 0.035 | 0.89 |
Autoencoder + MLP [22] | 85.7 | 0.041 | 0.87 |
LSTM-Based Encoder–Decoder [23] | 82.9 | 0.048 | 0.85 |
Performance Metrics
The proposed AEN-RFML with the ConvMixer/MLP-Mixer architecture performs exceedingly well on all the considered metrics. It achieves 94.2% modulation classification accuracy, which is very high and thus indicates highly accurate recognition of different RF signal types. The average reconstruction MSE of 0.023 suggests that the model faithfully reconstructs the signals after passing through noisy channels, with negligible distortion. Its latent-feature robustness, evaluated at 0.95 (cosine similarity), indicates that under such SNR regimes, the encoder preserves the essential characteristics of the signals with high stability and resilience, as shown in Table 3.
Table 3: Performance Metrics
Model | Modulation Accuracy | Avg Reconstruction MSE | Latent Feature Robustness |
ConvMixer | 94.2% | 0.023 | 0.95 |
