
+91 6002993949
submission@iarconsortium.org
Open Access
ISSN (Print) : 2708-5155
ISSN (Online) : 2708-5163
In this paper, a Biometric Identification system in which features are extracted by minimizing the residual of each training pose is proposed. Two non-orthogonal transforms, namely, Cosine (CT), and Haar Wavelet (HW) are successively employed to obtain the final people extracted feature models. First, the Cosine coefficients are calculated and only a predefined number of them are kept. Then, the rest of coefficients are transformed to the time domain through The Inverse Cosine transform. The HW is employed on the modified spatial pose, i.e., the residual, to obtain the Wavelet part of pose representation. The final feature matrix of each person in the dataset is composed of the coefficients from those two domains. The system is exhaustively tested on a publicly accessible dataset, the ORL, to prove the effectiveness of the proposed technique. The results show the amount of the storage requirement significant reduction, i.e., the system handles more people, without losing the recognition accuracy rates, which makes it an excellent candidate to be utilized in communications systems. The other design parameter, computational complexity, is also comparable with recently published algorithms.
The facial features of individuals are frequently employed as a biometric signal for the purpose of machine-based identification [1]. Face Recognition (FR) has various practical applications, including forensic analysis [2, 3], access control for facilities, and unlocking smartphones. The comprehensive literature survey in [4] provides an extensive review of face recognition techniques up until 2003. It covers a wide range of approaches, including holistic methods, local feature-based methods, and statistical models, offering valuable insights into the development of face recognition algorithms. The objective of the study presented in [5] is to introduce a new and robust algorithm for facial recognition. This algorithm combines three key components: principal component analysis (PCA) for feature extraction and dimensionality reduction, a technique based on Triplet Similarity Embedding (TSE). The experiment utilizes publicly available Olivetti Research Laboratory dataset to evaluate the correct accuracy achieved by the proposed algorithm and compare them against the performance of the popular k-Nearest Neighbor (kNN) classifier. The results of the experiments demonstrated that the proposed algorithm outperforms the kNN classifier. Furthermore, it is noted that in cases where the test set is larger than the training one, the presence of TSE has a more pronounced effect on the learning phase compared to its absence. The maximum reported results (textbf{for one random trial only}) when eight poses are allocated for training and other two are used for testing were: 98.75%, 98.75%, and 95% for PCA-TP, PCA-P, and kNN respectively. The paper in [7] presented an overview of various research studies on FR from multiple angles. It discussed the progression and advancements in FR, highlighting its application in real-world scenarios. The paper also provided insights into the evaluation criteria and databases commonly used in FR research. Additionally, it offered a forward-thinking perspective on the future of FR, emphasizing its potential for widespread adoption and numerous application possibilities.
Over the years, various methods, algorithms, approaches, and databases have been developed to explore face recognition in different scenarios, both controlled and uncontrolled [8]. In controlled environments, where factors like lighting, viewing angle, and camera-subject distance are regulated, 2D approaches have achieved a high level of recognition accuracy. However, when there are changes in ambient conditions or facial appearance, such as variations in lighting or facial expression, the performance of these methods significantly deteriorates. As an alternative solution, 3D approaches have been proposed to address these issues. The advantage of using 3D data is its ability to handle changes in pose and lighting, which improves the efficiency of recognition systems. However, 3D data is somewhat sensitive to changes in facial expressions. That review provided an overview of the history of face recognition technology, current state-of-the-art methodologies, and potential future directions. The focus is particularly on the latest databases and methods for 2D and 3D face recognition. Additionally, emphasis was placed on the use of deep learning techniques, which are currently prominent in this field. The review also examined unresolved issues and suggested potential research directions in facial recognition, aiming to serve as a reference point for topics that merit further investigation.
Challenges in FR involve different aspects of human facial appearance, such as variations in lighting conditions, image noise, scale, and pose. In [9], a new approach was presented to enhance the accuracy of face recognition by improving the Local Binary Pattern (LBP) algorithm through the application of advanced approaches. These approaches include Contrast alteration, Bilateral Filtering, image Histogram Equalizer, and Blending. The aim was to overcome the obstacles that hinder accurate face recognition, thus enhancing the overall performance of the system. The experimental results (on three datasets that were created by the researchers) demonstrate that their method achieves high levels of accuracy, reliability, and robustness, making it suitable for real-life applications like an automatic attendance management system.
In recent studies, researchers have been utilizing different combinations of recognition algorithms to improve the precision of object recognition. In [10], they focused on integrating the coherence of DWT and 4 distinct approaches. Firstly, error vector PCA. Secondly, eigenvector PCA. Thirdly, eigenvector of Linear Discriminant Analysis (LDA). Finally, Convolutional Neural Network (CNN). The results obtained from these approaches are combined using the entropy of detection probability and a Fuzzy system. The work concluded that the characteristics of the image and the diversity of the database dominate the accuracy of recognition. The combined approach proposed in that work achieved a recognition rate of 89.56% for the worst-case scenario and 93.34% for the best-case scenario on a couple of samples from Faces96 dataset [11]. These results demonstrate an improvement compared to previous studies that employed individual methods on specific sets of images.
Viola and Jones [12] presented the Viola-Jones framework, originally designed for real-time object detection, which later became instrumental in face detection. Their method utilizes Haar-like features and AdaBoost learning algorithm, providing robust and efficient face detection, which serves as a crucial step in many face recognition pipelines. The Deep Face algorithm proposed in [13] demonstrated significant advancements in face verification. That deep learning-based method employed a convolutional neural network (CNN) to learn discriminative features directly from raw pixels, achieving near-human performance on standard face recognition benchmarks. Face Net [14] introduced a landmark deep metric learning approach for face recognition. By training a CNN to directly optimize the similarity of face embeddings, Face Net achieved state-of-the-art performance in face recognition and enabled efficient face clustering based on learned feature representations. Recent research has documented multiple systems that make use of the Cosine Transform (as a Two-Dimension signal analysis 2D-DCT) and the Wavelet Transform (as a Two-Dimension signal analysis 2D-DWT) according to recent studies, as mentioned in [15] and [16]. In [15], the preprocessing steps involved converting the image to grayscale, resizing, applying Laplacian or Gaussian, and adjusting the intensity of gamma, detecting noise (Salt, and Pepper), and applying Weiner and Median filters. Thereafter, 2 wavelet decomposition stages were employed, with the applications of the final stage only to the Approximation region. The next step is to apply the Cosine formula to the Approximation region, and coefficients lay in the upper left corner were retained, known as Slope-form Triangular DCT. Additionally, [15] utilized a method to decrease the repetition of features. The peak results reported in [15] were 98.66%, 72%, and 91.86% for the JAFFE, color FERET, ORL datasets based on the average of 25 trials. In [16], introduced a feature selection method that sequentially applied cosine and wavelet on all training image poses. Support Vector Machine was employed as a classifier. The system evaluation in [16] involved using various levels of wavelets decomposition and different retained Cosine coefficients. The best outcome reported in [16] was an accuracy of 96.4% achieved on the ORL dataset. This was accomplished by employing 2 levels of DWT decomposition and using cosine coefficients as a fifteen-by-fifteen matrix. Furthermore, in situations where there are abundant computing resources, Deep Learning methods have proven effective when combined with conventional techniques for Face Recognition [18].
This paper presents the following contribution: we propose a new system for identifying people based on their faces. The system combines a mixed 2D-DWT (2D Discrete Wavelet Transform) and 2D-DCT (2D Discrete Cosine Transform) image representation. During the Training phase, we employ an algorithm to calculate the coefficient matrices in both domains for every facial pose, since these two domains are non-orthogonal to each other. This computation aims to minimize the residual error and capture as much of the image as possible. The selection of coefficients in each domain is based on their energy levels. The final model matrix for all poses allocated for training is formed by concatenating chosen retained coefficients in both aforementioned domains. During Testing mode, we compute Euclidean separations between each testing sample (specifically, its coefficients in both domains) and every training pose (specifically, its coefficients in both domains). We evaluate the performance of our system using the ORL dataset for testing the recognition system. The results show that our proposed system requires less storage space compared to systems that use only cosine, wavelet, or consecutively direct application of both. This makes our approach a practical option for face recognition. Moreover, a compact representation, carefully chosen, is often a better input choice for a classifier. Our system maintains or enhances the recognition rates compared to other systems under comparison. The subsequent sections of the paper are structured as follows: Section II presents an overview of wavelet and cosine in the context of face identification. Section III presents our proposed system in detail. Section IV presents the experimental results. Finally, we conclude in Section V.
The primary portion of the energy found in signals such as images is focused within a limited range of their Discrete Cosine Transform representation. Consequently, fewer counts of coefficients are sufficient to approximate the original signal when compared to the Spatial domain. The DCT transformation is frequently utilized in lossy compression techniques for widely used formats like JPEG images.
Haar wavelet [19, 20] is a mathematical function that forms the basis of the Haar wavelet transform, a widely used technique in signal and image processing. The Haar wavelet is a simple and efficient tool for analyzing and decomposing signals into different frequency components. The Haar wavelet transform operates by dividing a signal into consecutive non-overlapping intervals or segments and applying a set of Haar wavelet functions to each segment. This process results in a representation of the signal in terms of approximation and detail coefficients. The approximation coefficients capture the low-frequency components of the signal, while the detail coefficients capture the high-frequency components or the differences between consecutive samples.
Testing begins with preparing the pose sample through preprocessing, which involves resizing, the same steps that were implemented in the Training. We then calculate Euclidean separation (i.e., distance) between the train and test samples (its resulting cosine and wavelet matrices). These matrices are obtained by applying the same procedure done in Training to the test pose, as well as to all the final matrices of the training poses. By comparing these distances, we find the training pose from the gallery that is closest to the test pose. This closest training sample is declared as the correct match for each arrangement of coefficient selection. Finally, the recognition accuracy is obtained by taking the count of correctly identified poses and dividing it by the total count of testing images
Proposed approach is assessed by using a publicly available dataset called ORL [17]. Figure Fig. 2 displays raw samples from this dataset. The approach is compared to 5 other facial Identification systems. These methods utilize either the Cosine or Wavelet coefficients for feature extraction. These can be shortened by choosing a pre-established quantity or by combining elements from both domains. Truncation involves selecting and keeping a certain number of coefficients from a matrix, while disregarding the rest. Truncation can be implemented using regular or irregular geometric shapes that contain the coefficients. Typically, the upper left triangle or rectangle of the coefficient matrix is retained. Every possible combination of training and testing sets is assessed for every system. In Table 1, the term Config 1 represents the system where extracted features are the cosine coefficients after truncation, denoted as trun_cosine, and truncated HW, denoted as trun_wavelet. Truncation size is shown in Table 1. In the same fashion, Config 2 to Config 4 follows the same formation, except for Max_cosine , Max_wavelet that refer to selecting coefficients with the highest energy content in aforementioned domains, respectively. These systems have test steps that follow the same procedure as the presented approach. The ultimate choice for each system (Config 1 to Config 4) depends on the smaller value between two normalized minimum distances, which are calculated using the cosine and HW measures. The average rate of recognition in the tables is determined by taking the average of all the accuracy results obtained from various combinations of pose sets. To illustrate, in a single experiment, the dataset consists of 10 poses, with 5 poses allocated for training and the remaining 5 for testing. Consequently, there are ![]() potential combinations. In total, 837 different trials were conducted solely on this dataset to obtain the numbers shown in Tables 2 and 3. The term "peak recognition rate" indicates the highest level of accuracy that has been attained, while #T_r represents the number of poses assigned for training per individual in the dataset.
potential combinations. In total, 837 different trials were conducted solely on this dataset to obtain the numbers shown in Tables 2 and 3. The term "peak recognition rate" indicates the highest level of accuracy that has been attained, while #T_r represents the number of poses assigned for training per individual in the dataset.
To show the effect of the energy distribution between the two domains, a total number of 20 trails were executed for the proposed system. In these trials, the energy distribution ratio was selected from a vector that ranges from 40% to 60% where 50% simply means that the energy was equally distributed between the two domains. Fig. 3, and Fig. 4 show the peak and average results when #T_r=5 for the energy distribution ratio ranges between [40%,60%]. As shown in these figures, the performance of the system with DWT is better than the system performance with DCT/DWT when the energy ratio is less than 52%. On the other hand, the DCT/DWT outperforms DWT after that ratio.
4.1. Assessing the Performance of the System
The outcomes obtained for the ORL dataset [17] are presented in Tables 2 and Table 3. There are 40 individuals participating, with each person having 10 distinct poses in ORL.
4.2. Comments on the Proposed Approach
While the proposed system keeps fewer coefficients per pose, it manages to maintain the same level of computational complexity as the other systems being compared, particularly during the Testing phase. In the dataset that was examined, the proposed method decreases the average storage requirement per pose by around 62% in comparison to the other systems under evaluation. In comparison with [5] (the most recent reference), the proposed system outperforms the system in [5] in terms of recognition accuracy rates and system complexity. In [5], only one random trail was conducted and achieved 84.375% for 2 training poses. In this work, the system achieved 88.12% peak (out of 45 trails), and 82.69% (an average of 45 trails).
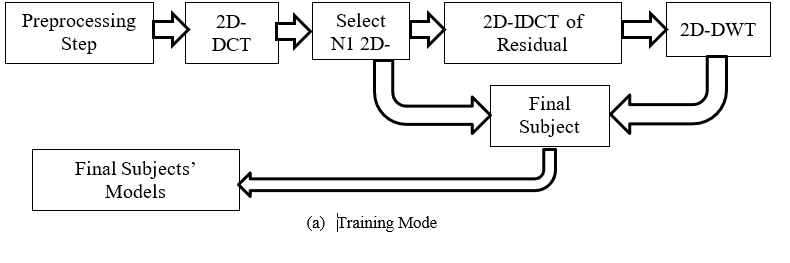
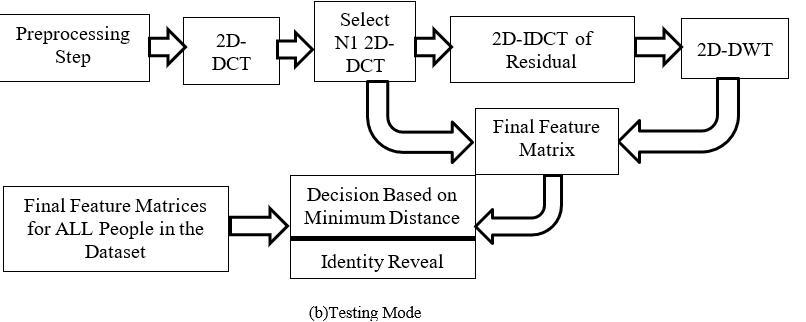

Figure 2. Raw Samples from the ORL dataset
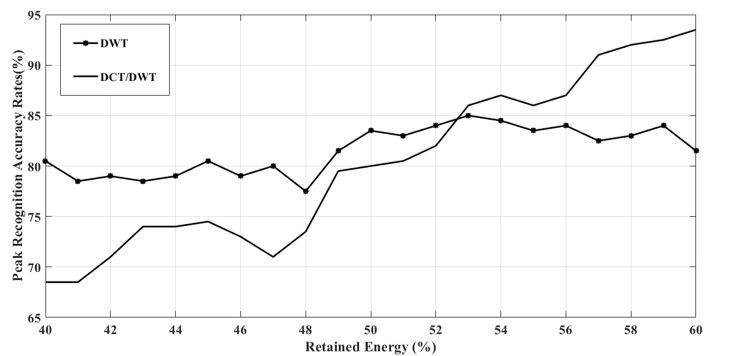
Figure 3. Peak Recognition Accuracy Rates as a Function of the Energy Distribution Ratio (when Tr=5)
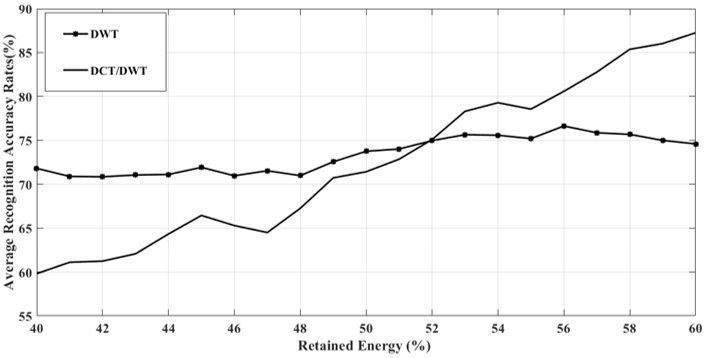
Figure 4. Average Recognition Accuracy Rates as a Function of the Energy Distribution Ratio (when Tr=5
Table 1: Matrices Sizes for Config 1 through Config 4
Config 1 | Config 2 | ||||
Truncated Cosine | Truncated Wavelet | Total | Maximum Cosine | Truncated Wavelets | Total |
6*6 | 32*32 | 1060 | 36 | 32*32 | 1060 |
Config 3 | Config 4 | ||||
Truncated Cosine | Maximum Wavelets | total | Maximum Cosine | Maximum Wavelets | Total |
6*6 | 400 | 436 | 36 | 400 | 436 |
Table 2: Peak Identification Rates
# Training Samples | Two | Three | Four | Five | Six |
Config 1 | 87.81 | 93.92 | 97.5 | 99 | 99.4 |
Config 2 | 86.88 | 94.64 | 96.67 | 98.5 | 99.4 |
Config 3 | 87.81 | 93.93 | 97.5 | 99 | 99.4 |
Config 4 | 86.88 | 94.64 | 96.67 | 98.5 | 99.4 |
Work in [15] | 85.31 | 92.15 | 95.42 | 97 | 98.13 |
This Work | 88.12 | 94.29 | 97.50 | 98.5 | 99.38 |
Table 3: Average Identification Rates
# Training Samples | Two | Three | Four | Five | Six |
Config 1 | 81.5 | 88.2 | 92 | 94.28 | 95.71 |
Config 2 | 81.5 | 88.15 | 91.98 | 94.27 | 95.71 |
Config 3 | 81.49 | 88.21 | 92.02 | 94.28 | 95.71 |
Config 4 | 81.48 | 88.15 | 91.98 | 94.27 | 95.71 |
Work in [15] | 79.47 | 85.84 | 89.61 | 91.96 | 93.57 |
This Work | 82.69 | 88.93 | 92.34 | 94.34 | 95.63 |
We proposed a face identification approach that employs a process of breaking down the image signal into separate domains using a wavelet and cosine transforms. This sequential decomposition of the image into these two chosen transform domains proves to be a more efficient representation of the image, while maintaining the same, or less, number of coefficients in those domains. In other words, compared to other techniques using different transform domains, our method results in zero residual energy of the facial pose without altering the count of retained coefficients. To evaluate thoroughly the approach, we conducted extensive experiments using the ORL dataset and compared it with several cutting-edge methods. The findings indicate that our system attains a comparable level of accuracy in recognizing and has a similar level of complexity as observed during the testing stage. Moreover, it manages to reduce storage needs by an average of 62%.
Acknowledgements: Not Applicable
Conflict of interest: The authors declare that there are no conflicts of interest regarding the publication of this manuscript.
Author Contribution Statement: Not Applicable
Daimi, Kevin, Guillermo Francia III, and Luis Hernández Encinas, eds. Breakthroughs in digital biometrics and forensics. Springer Nature, (2022). https://books.google.com/books?hl=en&lr=&id=FfiVEAAAQBAJ&oi=fnd&pg=PR5&dq=1.%09Daimi,+K.,+Francia+III,+G.,+%26+Encinas,+L.+H.+(Eds.).+(2022).+Breakthroughs+in+digital+biometrics+and+forensics.+Springer+Nature.+&ots=RIM0gtrVEw&sig=PdLN_OIDt-inof9UbbgedTFJHig.
Abdulhussain, Sadiq H., et al. "Face recognition algorithm based on fast computation of orthogonal moments." Mathematics 10.15 (2022): 2721. https://doi.org/10.3390/math10152721
Johansen, Gerard. Digital forensics and incident response. Packt Publishing Ltd, 2017. https://books.google.com/books?hl=en&lr=&id=4eZDDwAAQBAJ&oi=fnd&pg=PP1&dq=Johansen,+Gerard+(2020).+Digital+forensics+and+incident+response:+Incident+response+techniques+and+procedures+to+respond+to+modern+cyber+threats.+Packt+Publishing+Ltd.+&ots=aPzptJsozR&sig=ciuki1GbtS-CfqFQ20hlmJ3HQvo.
Zhao, Wenyi, et al. "Face recognition: A literature survey." ACM computing surveys (CSUR) 35.4 (2003): 399-458. https://doi.org/10.1145/954339.954342
Bazatbekov, Bek, et al. "2D face recognition using PCA and triplet similarity embedding." Bulletin of Electrical Engineering and Informatics 12.1 (2023): 580-586.DOI: 10.11591/eei.v12i1.4162.
Varish, Naushad, et al. "Color Image Retrieval Method Using Low Dimensional Salient Visual Feature Descriptors for IoT Applications." Computational Intelligence and Neuroscience 2023 (2023). https://www.hindawi.com/journals/cin/2023/6257573/.
Li, Lixiang, et al. "A review of face recognition technology." IEEE access 8 (2020): 139110-139120. DOI: 10.1109/ACCESS.2020.3011028.
Adjabi, Insaf, et al. "Past, present, and future of face recognition: A review." Electronics 9.8 (2020): 1188. https://doi.org/10.3390/electronics9081188.
Bah, Serign Modou, and Fang Ming. "An improved face recognition algorithm and its application in attendance management system." Array 5 (2020): 100014. https://doi.org/10.1016/j.array.2019.100014.
Tabassum, Fahima, et al. "Human face recognition with combination of DWT and machine learning." Journal of King Saud University-Computer and Information Sciences 34.3 (2022): 546-556. https://www.sciencedirect.com/science/article/pii/S1319157819309395.
Spacek, Libor. "Face Recognition Data., https://cmp.felk.cvut.cz/~spacelib/faces/faces96.html
Viola, Paul, and Michael J. Jones. "Robust real-time face detection." International journal of computer vision 57 (2004): 137-154. https://doi.org/10.1023/B:VISI.0000013087.49260.fb
Taigman, Yaniv, et al. "Deepface: Closing the gap to human-level performance in face verification." Proceedings of the IEEE conference on computer vision and pattern recognition. (2014), doi: 10.1109/CVPR.2014.220.
Schroff, Florian, Dmitry Kalenichenko, and James Philbin. "Facenet: A unified embedding for face recognition and clustering." Proceedings of the IEEE conference on computer vision and pattern recognition. (2015). doi: 10.1109/CVPR.2015.7298682.
Rao, Shilpashree, and MV Bhaskara Rao. "A novel triangular DCT feature extraction for enhanced face recognition." 2016 10th International Conference on Intelligent Systems and Control (ISCO). IEEE, 2016.DOI: 10.1109/ISCO.2016.7726977.
Wang, Meihua, Hong Jiang, and Ying Li. "Face Recognition based on DWT/DCT and SVM." 2010 International Conference on Computer Application and System Modeling (ICCASM 2010). Vol. 3. IEEE, (2010). https://10.1109/ICCASM.2010.5620666.
AT&T Laboratories Cambridge Database of Faces. https://cam-orl.co.uk/facedatabase.html
Balaban, Stephen. "Deep learning and face recognition: the state of the art." Biometric and surveillance technology for human and activity identification XII 9457 (2015): 68-75. https://doi.org/10.1117/12.2181526
Gonzalez, Rafael C., and Richard E. Woods. "Digital image processing. upper saddle River." J.: Prentice Hall (2002). https://dl.ebooksworld.ir/motoman/Digital.Image.Processing.3rd.Edition.www.EBooksWorld.ir.pdf.
Garcia, Christophe, George Zikos, and George Tziritas. "Wavelet packet analysis for face recognition." Image and Vision computing 18.4 (2000): 289-297. https://doi.org/10.1016/S0262-8856(99)00056-6.
